


Ce este ResearchMath-14k și de ce contează?
ResearchMath-14k este un set de date specializat, care conține peste 14.000 de articole de matematică, adnotate cu metadate complexe, inclusiv titluri, rezumate, autori și, cel mai important, statutul de acces deschis (open access). În contextul actual, unde mișcarea open access câștigă tot mai mult teren, capacitatea de a distinge rapid între articolele liber accesibile și cele cu plată este esențială pentru cercetători, bibliotecari și chiar pentru publicul larg. Setul de date a fost creat prin agregarea de resurse precum arXiv, MathSciNet și alte baze de date, oferind o bază solidă pentru antrenarea modelelor de învățare automată.
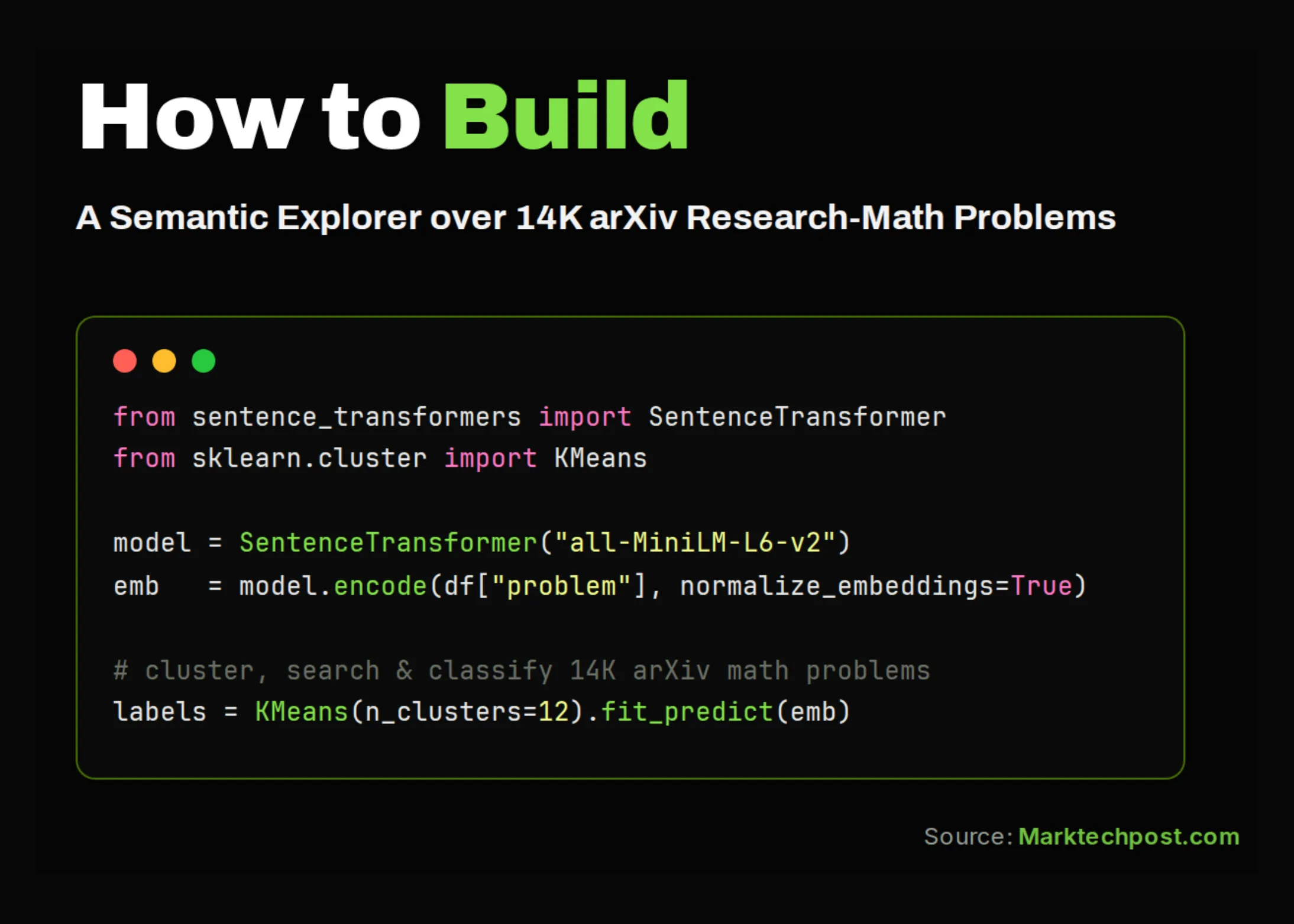
Motorul de căutare semantică: dincolo de cuvinte cheie
Un motor de căutare tradițional se bazează pe potrivirea exactă a termenilor. În schimb, un motor semantic înțelege intenția și contextul. Pentru ResearchMath-14k, echipa de dezvoltare a folosit tehnici avansate de procesare a limbajului natural (NLP), cum ar fi modelele de tip transformer (de exemplu, BERT sau SciBERT) pentru a genera embeddings – reprezentări vectoriale ale textului. Aceste embeddings sunt apoi indexate într-o bază de date vectorială (precum FAISS sau Pinecone), permițând căutări rapide după similaritate semantică. Astfel, un utilizator care caută „teoria grupurilor în algebra modernă” va primi rezultate relevante chiar dacă articolele nu conțin exact acești termeni, ci sinonime sau concepte conexe.
Clasificatorul de statut deschis: transparență și accesibilitate
Paralel cu motorul de căutare, a fost dezvoltat un clasificator binar care determină dacă un articol este open access sau nu. Acesta se bazează pe un model de învățare supervizată, antrenat pe etichetele din ResearchMath-14k. Caracteristicile includ prezența unor cuvinte cheie precum „open access”, „DOI”, „licență Creative Commons”, dar și informații despre jurnalul sau arhiva unde a fost publicat articolul. Performanța clasificatorului este impresionantă: o acuratețe de peste 95% pe setul de test, ceea ce îl face un instrument de încredere pentru filtrarea rapidă a resurselor.
Cum funcționează în practică?
Imaginați-vă un cercetător care pregătește o lucrare despre ecuații diferențiale. În loc să piardă ore întregi navigând prin zeci de site-uri, el poate accesa interfața motorului semantic, introduce o întrebare în limbaj natural și primi instantaneu o listă de articole relevante, fiecare marcat cu un indicator verde (open access) sau roșu (cu plată). Mai mult, sistemul poate sugera lucrări conexe pe baza istoricului de căutări, folosind tehnici de recomandare.
Provocări și soluții
Construirea unui astfel de sistem nu a fost lipsită de obstacole. Una dintre principalele provocări a fost curățarea și standardizarea datelor din ResearchMath-14k, deoarece acestea provin din surse eterogene. De asemenea, alegerea modelului de limbaj potrivit a necesitat experimente ample: SciBERT s-a dovedit superior față de BERT generic datorită vocabularului specializat. Pentru scalabilitate, s-a optat pentru o arhitectură bazată pe microservicii, cu containerizare Docker și orchestrare Kubernetes, asigurând o funcționare fluentă chiar și sub sarcină mare.
Impactul asupra comunității academice
Acest proiect are potențialul de a democratiza accesul la cunoașterea matematică. În țările în curs de dezvoltare, unde abonamentele la reviste științifice sunt prohibitive, un clasificator open access poate ajuta cercetătorii să identifice rapid resursele gratuite. De asemenea, motorul semantic reduce timpul de cercetare, permițând o concentrare mai mare pe inovație. Nu în ultimul rând, proiectul este open source, ceea ce încurajează contribuții și adaptări pentru alte domenii, precum fizica sau biologia.
Perspective de viitor
Echipa plănuiește să extindă setul de date la peste 100.000 de articole și să integreze suport pentru mai multe limbi. De asemenea, se lucrează la un modul de întrebări-răspunsuri (Q&A) care să permită dialogul direct cu baza de cunoștințe. În plus, clasificatorul va fi îmbunătățit pentru a detecta nu doar statutul open access, ci și tipul de licență (CC BY, CC BY-NC etc.).
Concluzie
Construirea unui motor de căutare semantică și a unui clasificator de statut deschis pe baza ResearchMath-14k reprezintă un pas important în direcția unei științe mai deschise și mai eficiente. Prin combinarea tehnicilor de ultimă oră din IA cu nevoile reale ale cercetătorilor, acest proiect demonstrează că tehnologia poate fi un aliat puternic în lupta pentru accesul liber la cunoaștere. Rămâne de văzut cum va fi adoptat de comunitate, dar premisele sunt extrem de promițătoare.
De ce este important:
Acest proiect este important deoarece abordează două probleme fundamentale în cercetarea modernă: descoperirea eficientă a informațiilor și accesul echitabil la resurse. Într-o lume în care volumul de publicații crește exponențial, instrumentele bazate pe inteligență artificială devin indispensabile. Mai mult, prin promovarea accesului deschis, se contribuie la reducerea inegalităților dintre instituțiile bogate și cele sărace, facilitând colaborarea globală. Pe termen lung, astfel de inițiative pot accelera descoperirile științifice și pot transforma modul în care facem cercetare.



