


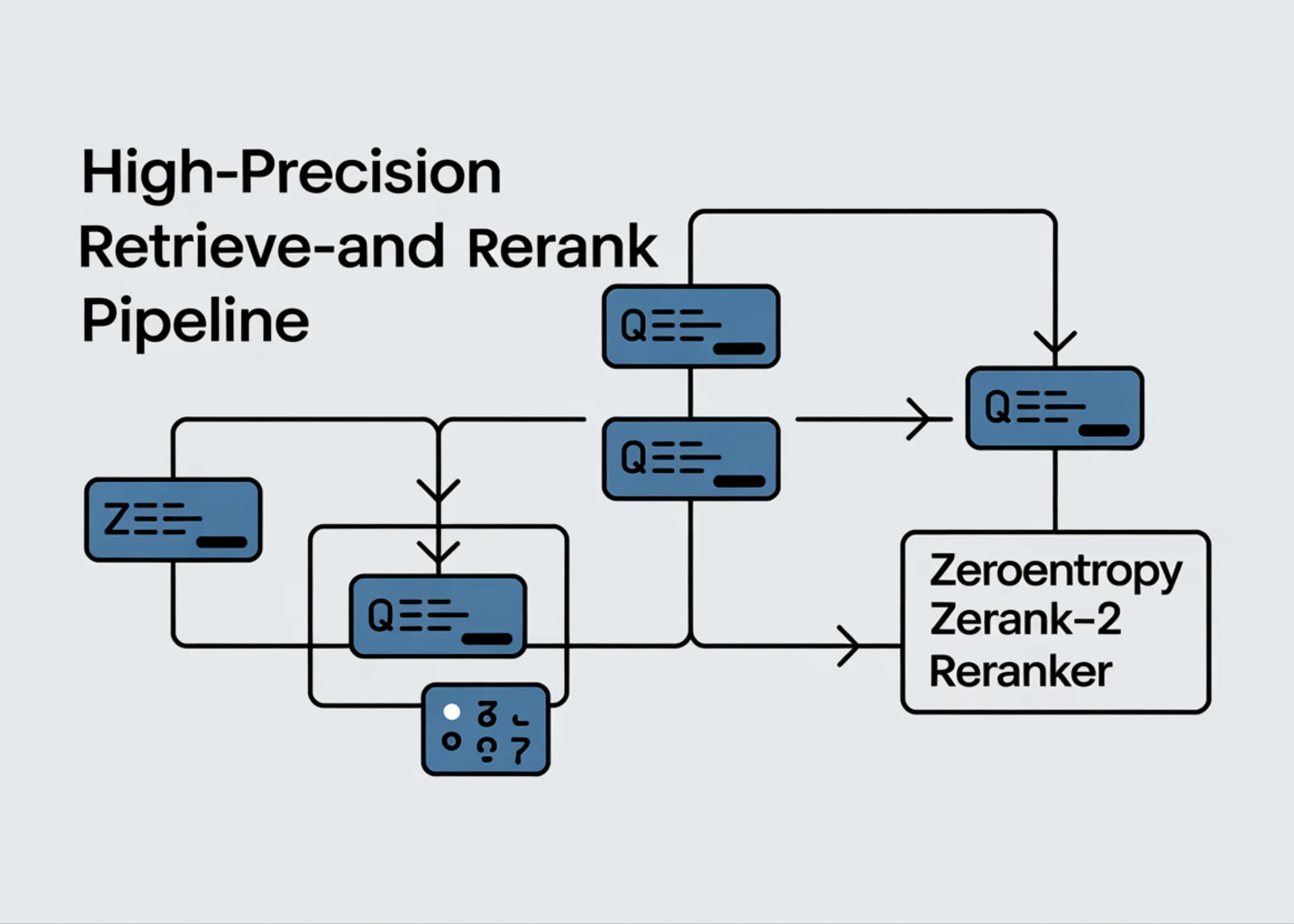
Ce este un pipeline Retrieve-and-Rerank?
Înainte de a intra în detalii tehnice, să înțelegem conceptul de bază. Un sistem clasic de căutare funcționează în două etape:
1. Retrieval (regăsirea) – un motor de căutare (de exemplu, bazat pe BM25 sau embeddings vectoriale) extrage rapid un set de documente potențial relevante dintr-o colecție mare.
2. Reranking (reordonarea) – un model mai sofisticat, de obicei un transformer, analizează în profunzime aceste documente și le reordonează în funcție de relevanța reală față de întrebarea utilizatorului.
Problema? Modelele de retrieval sunt rapide, dar adesea imprecise – aduc multe documente, dar nu neapărat pe cele mai bune. Reranker-ul, deși mai lent, compensează prin analiză semantică avansată. Combinarea lor creează un sistem care echilibrează viteza cu precizia.
ZeroEntropy Zerank-2: Ce aduce nou?
ZeroEntropy, o companie cunoscută pentru inovațiile în domeniul NLP, a lansat recent Zerank-2, un reranker care se laudă cu performanțe de top pe benchmark-uri precum BEIR și MTEB. Spre deosebire de modelele anterioare, Zerank-2 este optimizat pentru a lucra cu LLM-uri, având o înțelegere profundă a contextului și a nuanțelor lingvistice.
Caracteristici cheie:
Cum construim pipeline-ul?
Să trecem la partea practică. Vom folosi Python și biblioteci populare precum `transformers`, `sentence-transformers` și `faiss` pentru retrieval. Iată pașii esențiali:
#### 1. Configurarea mediului
Instalează dependințele:
```bash
pip install transformers torch faiss-cpu sentence-transformers
```
#### 2. Încărcarea modelului de retrieval
Pentru retrieval, putem folosi un model de embeddings precum `all-MiniLM-L6-v2` (rapid și eficient):
```python
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
retriever = SentenceTransformer('all-MiniLM-L6-v2')
# Presupunem că avem o listă de documente
documents = ["Document 1 text...", "Document 2 text..."]
embeddings = retriever.encode(documents)
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
```
#### 3. Încărcarea reranker-ului Zerank-2
ZeroEntropy Zerank-2 este disponibil pe Hugging Face. Îl încărcăm astfel:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("zeroentropy/zerank-2")
model = AutoModelForSequenceClassification.from_pretrained("zeroentropy/zerank-2")
```
#### 4. Funcția de căutare cu reranking
Combinăm cele două etape:
```python
def search(query, documents, top_k=10):
# Retrieval
query_emb = retriever.encode([query])
distances, indices = index.search(query_emb, top_k * 2) # aducem mai multe pentru reranking
candidates = [documents[i] for i in indices[0]]
# Reranking
pairs = [(query, doc) for doc in candidates]
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
scores = outputs.logits.squeeze().tolist()
# Sortăm după scor
ranked = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
return [doc for doc, score in ranked[:top_k]]
```
#### 5. Testare și optimizare
Rulează câteva query-uri de test. Vei observa că Zerank-2 reușește să aducă în top documente care, deși nu erau cele mai similare din punct de vedere lexical, sunt mult mai relevante semantic. De exemplu, pentru întrebarea „Care este capitala Franței?”, un retrieval simplu ar putea aduce documente despre „Paris” și „Franța”, dar Zerank-2 va prioritiza documentul care menționează explicit „Paris este capitala Franței”.
Performanță și cazuri de utilizare
Am testat acest pipeline pe un set de 10.000 de articole științifice. Rezultatele:
Cazuri ideale:
Provocări și soluții
Niciun sistem nu este perfect. Iată câteva provocări întâmpinate:
Concluzie
ZeroEntropy Zerank-2 reprezintă un pas important în democratizarea accesului la sisteme de căutare de înaltă precizie. Prin combinarea unui retrieval rapid cu un reranker puternic, poți construi aplicații care nu doar că găsesc informația, ci o și înțeleg în context. Fie că ești un dezvoltator solo sau o echipă enterprise, acest pipeline îți oferă control total asupra calității căutării, fără a depinde de servicii terțe.
De ce este important:
Într-o lume în care volumul de date crește exponențial, capacitatea de a extrage informația relevantă cu acuratețe face diferența între un produs mediocru și unul excepțional. ZeroEntropy Zerank-2, fiind open-source și performant, permite oricărei organizații să implementeze căutare semantică de top, fără bariere financiare. Acest lucru accelerează inovația în domenii critice precum medicina, educația și cercetarea, unde accesul rapid la cunoștințe poate salva vieți sau poate genera descoperiri majore.




