


Pentru cineva care nu a lucrat zilnic cu transformatoare, termenii pot suna ca un blestem tehnic, însă ce se întâmplă aici e mult mai interesant decât pare la prima vedere. Transformatoarele, coloana vertebrală a modelelor precum GPT, Claude sau Llama, se bazează pe un mecanism de atenție care calculează, pentru fiecare cuvânt dintr-o propoziție, cât de mult trebuie să „se uite" la celelalte cuvinte. Atenția clasică, bazată pe softmax, este precisă, dar extrem de costisitoare din punct de vedere computațional. Pe măsură ce fereastra de context crește, costul crește pătrat, ceea ce devine rapid insuportabil pentru secvențe lungi.
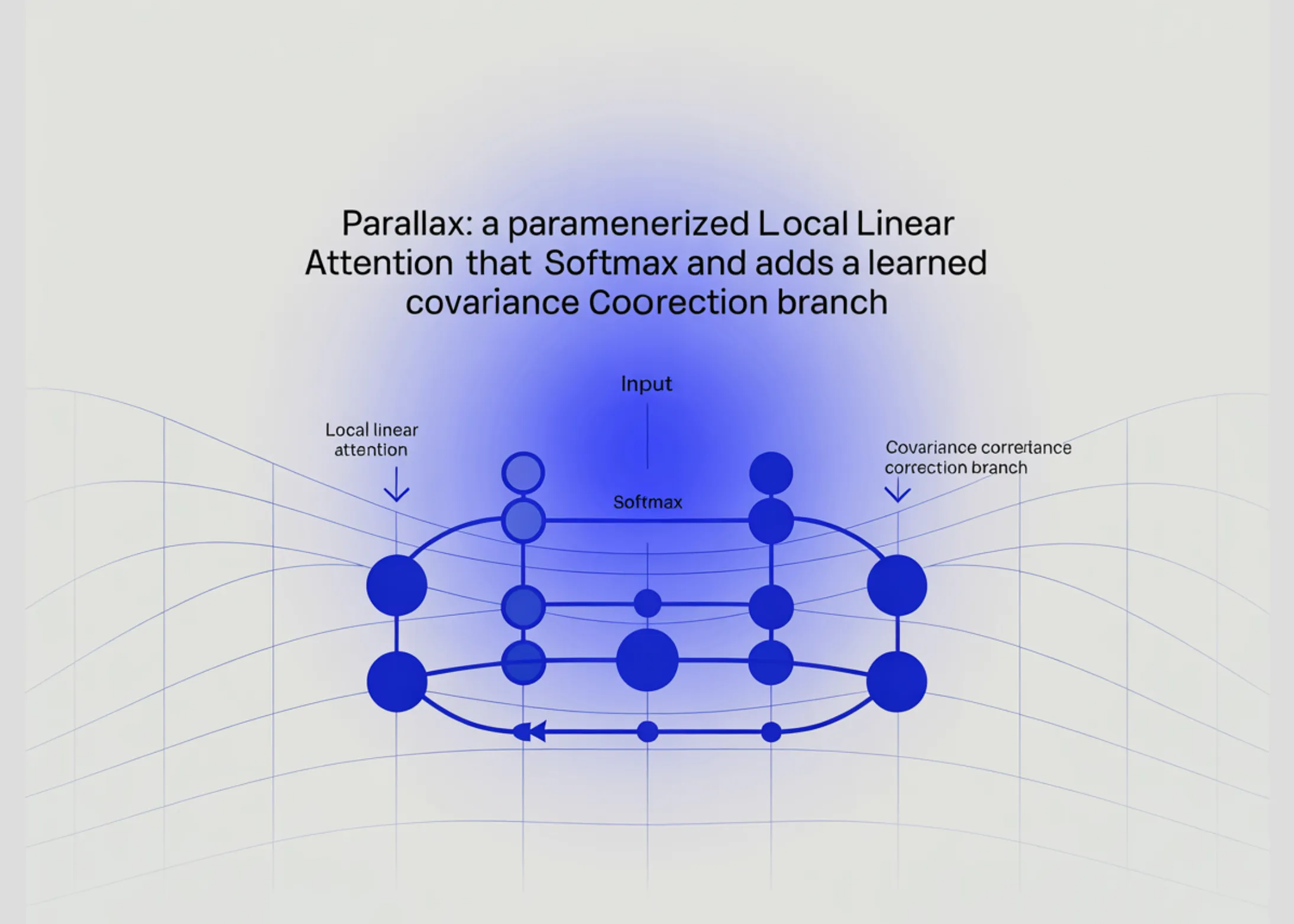
Aici intervin abordările de atenție liniară, care promit un cost mult mai mic. Multe dintre acestea, însă, aruncă peste bord funcția softmax, ceea ce le face rapide, dar le pierde din acuratețe. Parallax vine cu o idee îndrăzneață: de ce să arunci softmax-ul când poți să-l păstrezi și să adaugi, în paralel, o mică rețea secundară care învață corecțiile de covarianță? Exact asta face lucrarea.
Mai exact, Parallax propune o arhitectură hibrid. Pe de o parte, menține fluxul clasic de atenție softmax pentru a păstra proprietățile care au făcut transformatoarele atât de puternice. Pe de altă parte, introduce o a doua ramură, una ușoară, care învață, în mod explicit, structura de covarianță dintre token-uri. Această ramură de corecție este, în esență, un model liniar local, parametrizabil, care rulează în paralel cu atenția principală. Rezultatele celor două fluxuri sunt apoi combinate, oferind modelului final o reprezentare mai bogată decât ar putea oferi oricare dintre cele două mecanisme luate separat.
De ce e importantă corecția de covarianță? Gândiți-vă la un eseu lung. Atenția softmax vă spune, cuvânt cu cuvânt, ce relații există în text. Dar dacă vreți să capturați tipare care se întind pe mai multe paragrafe, pe structuri recurente, pe distribuții statistice care apar lent, softmax-ul singur poate fi prea local, prea fragil. Covarianța, în schimb, surprinde exact aceste dependențe de ordinul doi, adică modul în care token-urile variază împreună, nu doar dacă „se uită" unele la altele. Ramura de corecție a lui Parallax învață tocmai aceste tipare.
Un alt detaliu tehnic demn de menționat: prin faptul că este locală, ramura de covarianță nu explodează computațional. Ea operează pe ferestre definite, ceea ce menține costurile sub control și face ca Parallax să fie scalabil la contexte lungi fără a necesita memorii GPU imposibile. Practic, autorii reușesc un compromis elegant între acuratețea softmax-ului clasic și viteza mecanismelor liniare.
Comunitatea de pe rețele sociale a început deja să discute aprins lucrarea. Pe Discord, LinkedIn, Reddit și X, cercetători și ingineri comentează rezultatele preliminare. Mulți subliniază că abordarea e diferită de tentativele anterioare de a „distila" atenția, pentru că nu înlocuiește nimic, ci completează. Alții sunt mai prudenți și așteaptă codul de referință, care, potrivit unor surse, ar urma să fie publicat în curate, alături de ponderile antrenate. Acest lucru e important, pentru că, în mod tradițional, multe arhitecturi interesante au rămas doar niște exerciții teoretice din lipsă de implementări practice.
Din punct de vedere practic, Parallax ar putea schimba felul în care construim modele pentru sarcini care cer contexte foarte lungi: analiză de documente juridice, rezumare de cărți întregi, generare de cod pe fișiere ample, conversații care trebuie să-și amintească ore întregi de istoric. Un mecanism de atenție care combină precizia cu viteza, fără a face rabaturi masive, e Sfântul Graal pentru multe echipe de produs.
Mai există, desigur, întrebări legitime. Cum se comportă Parallax la scară, pe miliarde de parametri? Ramura de covarianță nu introduce, cumva, un bias care distorsionează atenția softmax? Care e impactul asupra antrenării, în termeni de stabilitate? Autorii propun experimente promițătoare, dar comunitatea va trebui să reproducă și să extindă aceste rezultate înainte de a declara un câștigător.
Cert este că direcția e una sănătoasă. Anii în care arhitectura transformatorului era considerată „rezolvată" s-au încheiat. Au apărut State Space Models, mecanisme de atenție sparse, abordări bazate pe memorie diferențiabilă, iar acum Parallax, cu combinația sa de softmax păstrat și corecție de covarianță învățată. Competiția e acerbă, iar utilizatorii finali au doar de câștigat, pentru că fiecare inovație mică se traduce, până la urmă, în chatboți mai rapizi, traduceri mai bune, cod mai corect.
Rămâne de văzut dacă Parallax va deveni noul standard sau doar o altă piesă dintr-un puzzle mai mare. Dar merită urmărit. Iar dacă lucrarea va fi acompaniată de cod deschis și ponderi, așa cum sugerează mai multe voci, atunci impactul ar putea fi imediat. Până atunci, dezbaterea continuă, iar AI-ul nu dă semne că ar încetini.
De ce este important:
Parallax este important pentru că propune o soluție hibridă elegantă la una dintre cele mai presante probleme ale momentului: scalabilitatea mecanismului de atenție. Păstrând softmax-ul, autorii nu sacrifică calitatea pe care oamenii o asociază cu transformatoarele moderne, iar prin adăugarea unei ramuri locale de corecție a covarianței, deschid calea spre contexte mult mai lungi, la costuri computaționale rezonabile. Într-o industrie în care fiecare punct de acuratețe și fiecare milisecundă de latență contează, o arhitectură care reușește să combine cele mai bune trăsături ale două lumi este un pas înainte, nu o simplă optimizare incrementală.




