


Ce este Gradient Descent?
Gradient descent este algoritmul de bază din spatele majorității modelelor de machine learning. Ideea e simplă: avem o funcție de pierdere (loss) pe care vrem să o minimizăm. Calculăm gradientul – direcția în care funcția crește cel mai rapid – și apoi facem un pas în direcția opusă. Repetăm acest proces până când ajungem la un minim local sau global.
Matematic, actualizarea parametrilor arată așa:
θ = θ - η * ∇L(θ)
unde η este rata de învățare (learning rate), iar ∇L(θ) este gradientul pierderii.
Pare simplu, nu? Dar în practică, lucrurile se complică atunci când peisajul funcției de pierdere nu este o simplă parabolă, ci un teren accidentat, cu văi înguste și pante abrupte.
De ce zigzaghează?
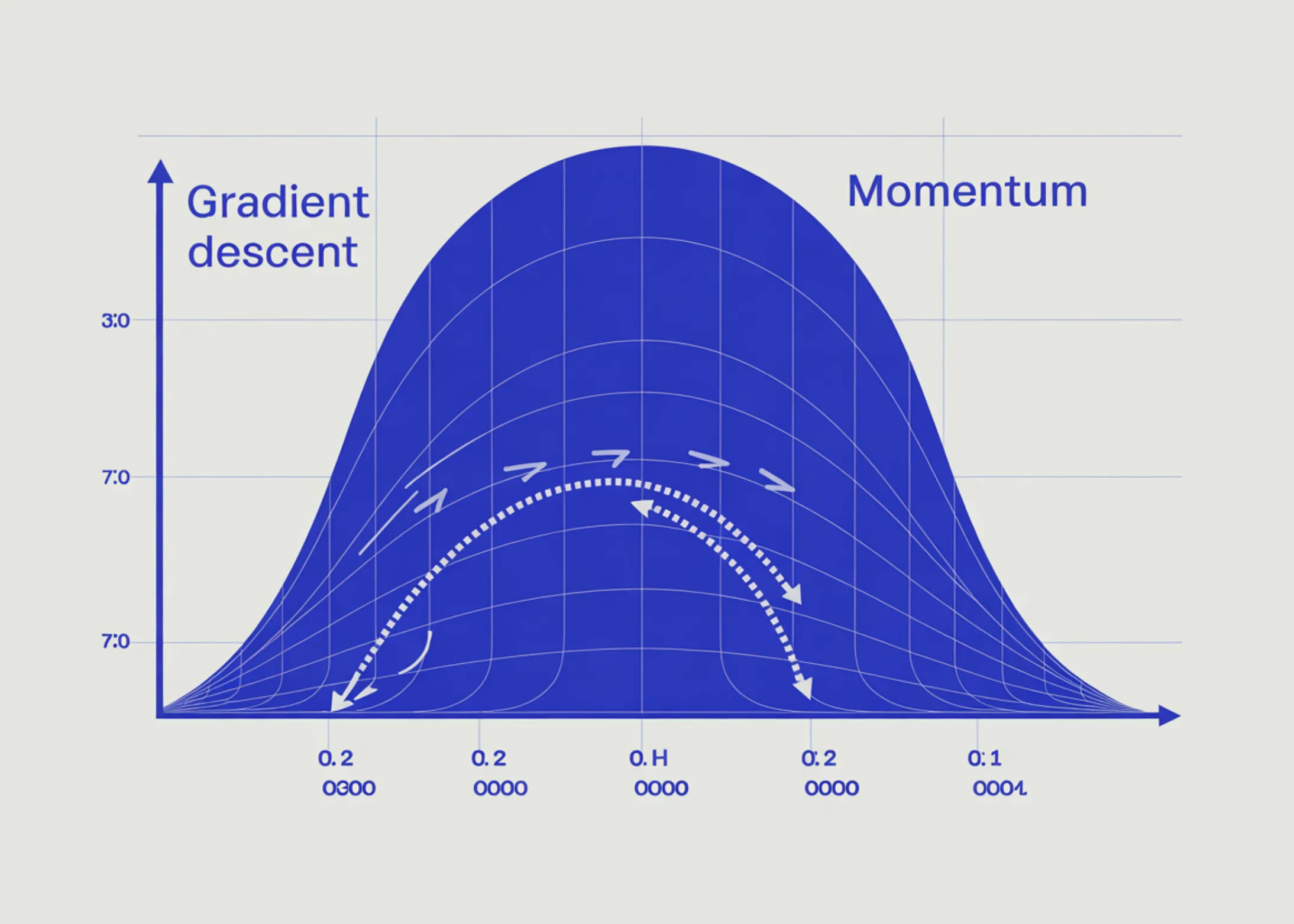
Problema zigzagării apare atunci când gradientul are componente de magnitudini foarte diferite. Imaginează-ți o vale lungă și îngustă, ca un canion. Gradientul pe direcția lungă a văii este mic (panta este lină), dar pe direcția transversală (peretele canionului) gradientul este uriaș. Când aplici gradient descent standard, vei face pași mari în direcția transversală, sărind dintr-un perete în altul, și pași mici de-a lungul văii. Rezultatul? O traiectorie în zigzag, care înaintează greu spre minim.
Acest comportament este frecvent în rețelele neuronale, mai ales când caracteristicile de intrare sunt pe scări diferite sau când arhitectura rețelei creează curburi diferite în spațiul parametrilor. De exemplu, într-o rețea convoluțională, gradientii pentru straturile timpurii pot fi mult mai mici decât cei pentru straturile finale, ducând la oscilații.
Un alt factor este prezența minimelor locale plate sau a „platourilor” – regiuni unde gradientul este aproape zero. În aceste zone, algoritmul poate rămâne blocat sau poate începe să oscileze fără a progresa.
Cum ajută Momentum?
Momentum este o tehnică inspirată din fizică. În loc să actualizăm parametrii doar pe baza gradientului curent, adăugăm o fracțiune din actualizarea anterioară. Practic, simulăm o bilă care rulează pe suprafața funcției de pierdere: ea acumulează viteză (momentum) și continuă să se miște în aceeași direcție, chiar dacă gradientul curent este mic sau oscilează.
Formula de actualizare devine:
v = β v - η ∇L(θ)
θ = θ + v
Aici, v este vectorul viteză, iar β (de obicei 0.9) este coeficientul de amortizare. Când gradientul schimbă brusc direcția (ca în zigzag), momentum-ul „netezește” tranziția, reducând oscilațiile. În plus, în zonele cu gradient mic, viteza acumulată ajută la traversarea rapidă a platourilor.
Efectul în practică
Să luăm un exemplu simplu: optimizarea unei funcții pătratice cu o vale alungită. Fără momentum, gradient descent face pași mici de-a lungul văii și pași mari transversal, producând un zigzag vizibil. Cu momentum (β=0.9), traiectoria devine aproape dreaptă, iar convergența este mult mai rapidă.
În rețelele neuronale profunde, momentum este aproape standard. Variante precum Adam, RMSprop sau Nesterov momentum sunt extensii care combină momentum cu adaptarea ratei de învățare per parametru. De exemplu, Adam folosește atât momentum (media exponențială a gradientilor) cât și o estimare a varianței gradientilor, ceea ce îl face robust la zigzaguri și la scări diferite.
Limitări și atenționări
Momentum nu este un leac universal. Dacă β este prea mare (ex: 0.99), viteza poate deveni excesivă, iar algoritmul poate sări peste minim sau să oscileze în jurul lui. De asemenea, în prezența minimelor locale ascuțite, momentum poate „sări” peste ele, ceea ce uneori este bun (evită capcanele), dar alteori poate duce la instabilitate.
O altă problemă apare atunci când gradientul este zgomotos (de exemplu, în stochastic gradient descent cu batch-uri mici). Momentum amplifică zgomotul dacă nu este calibrat corect. De aceea, multe implementări includ un termen de decay sau folosesc Nesterov momentum, care calculează gradientul în punctul „viitor” estimat, reducând overshooting-ul.
Concluzie
Zigzagarea gradient descent este un simptom al unui peisaj de optimizare neuniform. Momentum oferă o soluție simplă și eficientă, transformând un optimizator oscilant într-unul care „știe” să mențină direcția. Înțelegerea acestui mecanism te ajută nu doar să alegi mai bine hiperparametrii, ci și să depanezi problemele de convergență în modelele tale.
De ce este important:
În era inteligenței artificiale, optimizarea eficientă este cheia pentru antrenarea rapidă a modelelor complexe. Fără momentum, multe rețele neuronale ar necesita mult mai multe iterații pentru a converge, iar unele nu ar converge deloc. Cunoașterea acestor concepte te diferențiază ca practician și îți permite să construiești soluții mai robuste. Pe scurt, momentum nu este doar un truc – este o componentă fundamentală a optimizării moderne.




