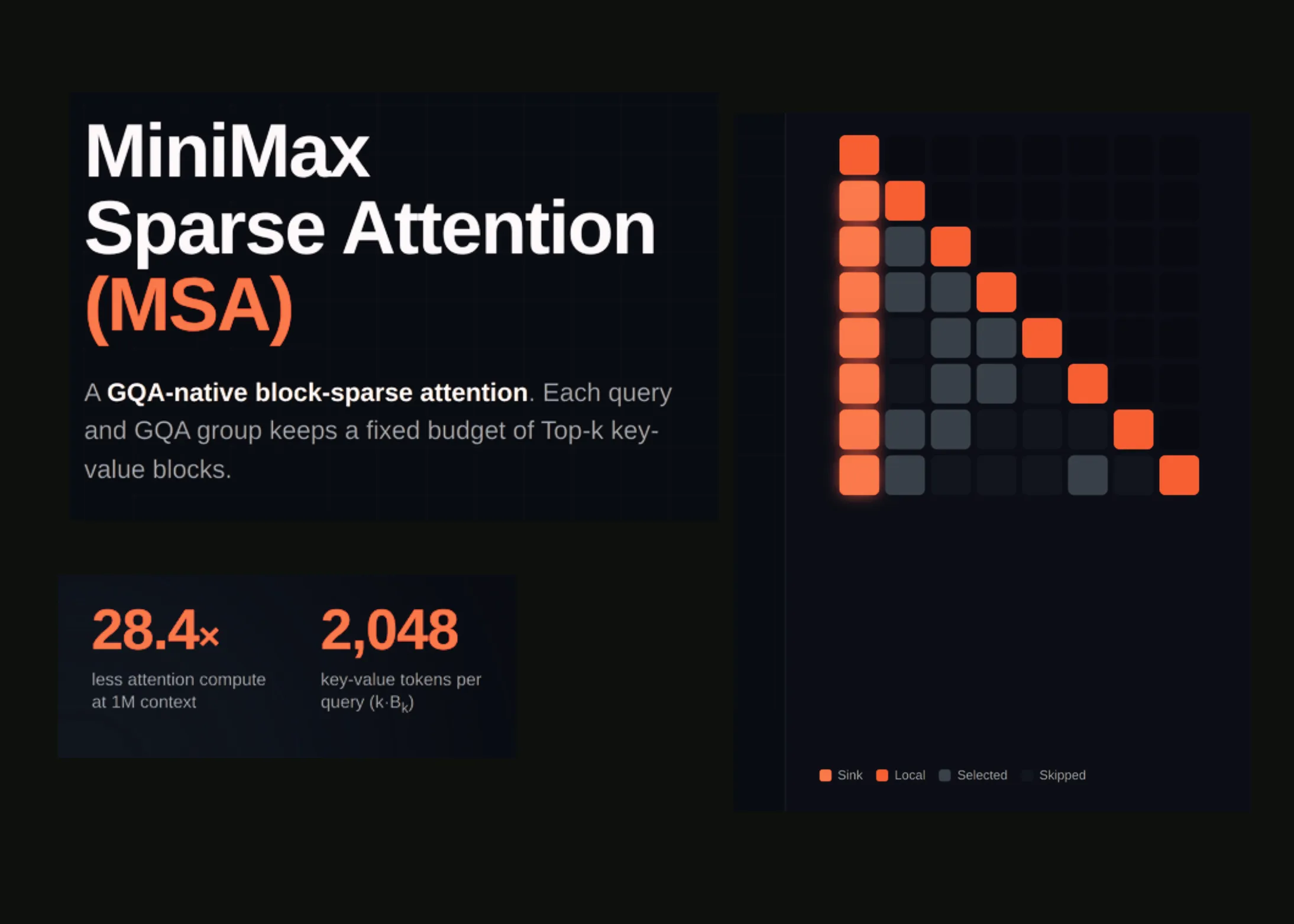
MiniMax Sparse Attention (MSA): O Revoluție în Atenția Dispersată cu Două Ramuri, Antrenată pe un Model MoE de 109 Miliarde de Parametri cu un Buget de 3 Tiloane de Token-uri
MiniMax Sparse Attention (MSA) este o arhitectură inovatoare de atenție dispersată cu două ramuri, antrenată pe un model MoE de 109 miliarde de parametri cu un buget de 3 trilioane de token-uri. MSA combină atenția locală și globală pentru a reduce costul computațional, permițând modelelor să gestioneze contexte mai lungi eficient. Această tehnologie ar putea democratiza accesul la AI și permite aplicații noi.
🕒 3 zile în urmă