


Pentru a înțelege cu adevărat semnificația MSA, trebuie să ne întoarcem la elementele de bază ale modelelor de limbaj mari (LLM-uri). Aceste modele, precum GPT-4 sau Llama, se bazează pe mecanisme de atenție pentru a procesa și a genera text. Atenția este, în esență, un mecanism care permite modelului să se concentreze pe părți relevante ale intrării atunci când produce o ieșire. În forma sa clasică, atenția este „plină” (full attention), ceea ce înseamnă că fiecare token din secvență se uită la toate celelalte token-uri. Acest lucru este extrem de puternic, dar vine cu un cost computațional uriaș, care crește pătratic cu lungimea secvenței. Pentru secvențe lungi, acest cost devine prohibitiv, limitând practic lungimea contextului pe care modelele îl pot gestiona eficient.
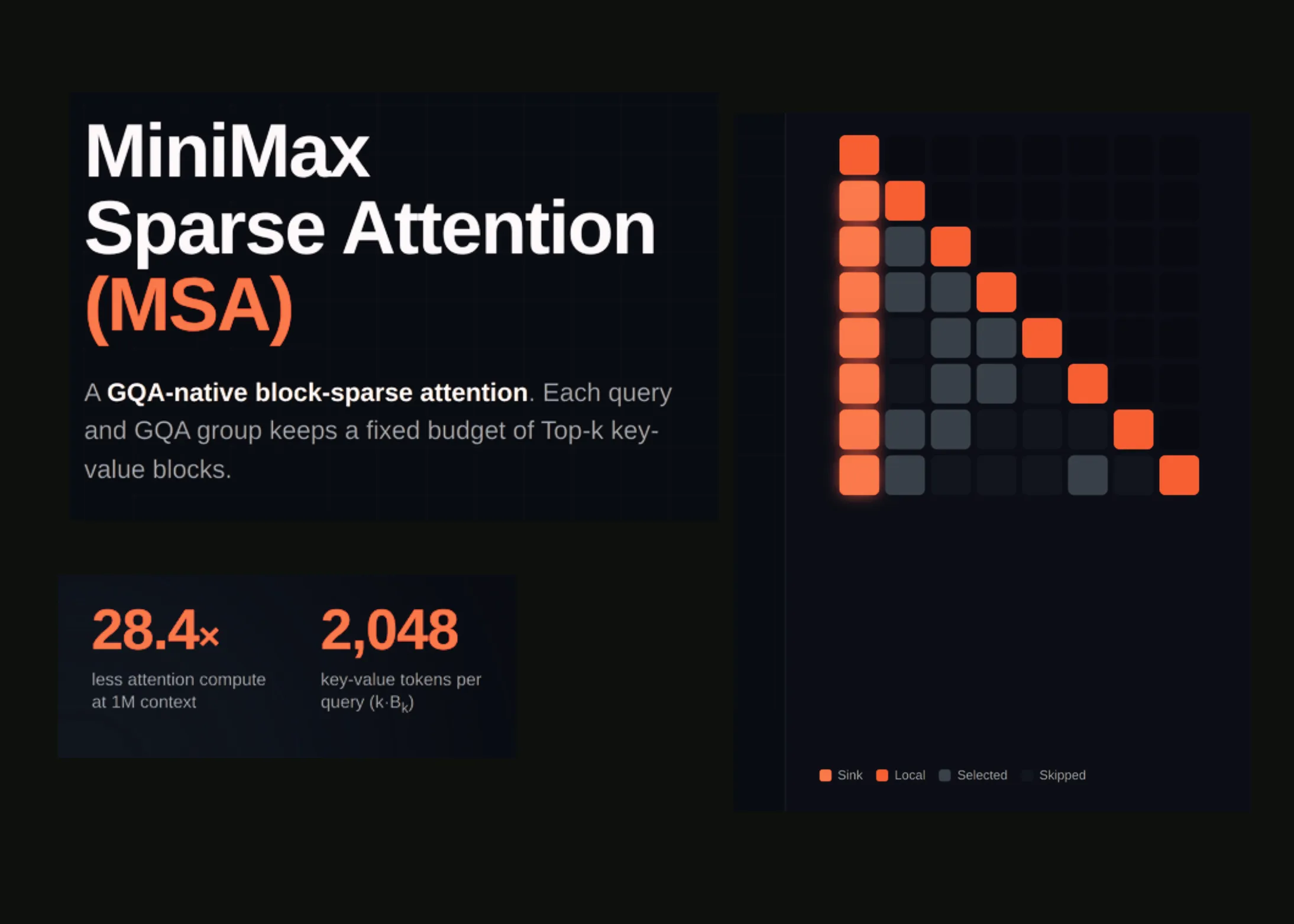
Aici intervine atenția dispersată (sparse attention). Ideea este simplă, dar genială: în loc să calculezi atenția pentru toate perechile de token-uri, calculezi doar pentru un subset selectat. Acest subset poate fi determinat în diverse moduri: fie prin pattern-uri fixe (de exemplu, atenție locală, unde fiecare token se uită doar la vecinii săi), fie prin pattern-uri învățate, unde modelul decide dinamic la ce să se uite. MSA duce acest concept la un nivel superior, introducând o arhitectură cu două ramuri (two-branch) care combină avantajele ambelor abordări.
Prima ramură a MSA este responsabilă pentru atenția locală, concentrându-se pe relațiile dintre token-urile apropiate. Aceasta este eficientă din punct de vedere computațional și captează dependențele locale, esențiale pentru înțelegerea sintaxei și a structurii imediate a textului. A doua ramură, pe de altă parte, se ocupă de atenția globală, dar într-un mod dispersat. În loc să calculeze atenția pentru toate perechile posibile, ea selectează un set de token-uri „globale” (de exemplu, token-uri speciale sau token-uri cu o importanță ridicată) și calculează atenția doar între acestea și restul secvenței. Această abordare reduce dramatic costul computațional, permițând modelului să gestioneze secvențe mult mai lungi fără a sacrifica prea mult din capacitatea de a capta dependențe la distanță.
Ceea ce face MSA cu adevărat special este modul în care aceste două ramuri sunt integrate. Ele nu funcționează independent, ci colaborează pentru a produce o reprezentare unificată a atenției. Această colaborare este învățată în timpul antrenamentului, ceea ce înseamnă că modelul însuși decide cum să combine informațiile locale și globale pentru a obține cele mai bune rezultate. Rezultatul este un mecanism de atenție care este atât eficient, cât și puternic, capabil să rivalizeze cu atenția plină în ceea ce privește calitatea, dar la o fracțiune din cost.
Antrenarea MSA pe un model MoE de 109 miliarde de parametri cu un buget de 3 trilioane de token-uri nu este o coincidență. Modelele MoE sunt ele însele o inovație în domeniul eficienței, permițând antrenarea unor modele masive fără a crește proporțional costul computațional. În esență, un model MoE este compus din mai multe „sub-modele” (experți), iar pentru fiecare token, doar un subset de experți este activat. Aceasta înseamnă că, deși modelul are un număr mare de parametri, doar o fracțiune dintre ei este folosită pentru fiecare calcul, ceea ce reduce semnificativ cerințele de memorie și timp de procesare. Combinarea MSA cu un model MoE este o mișcare strategică: MSA reduce costul atenției, iar MoE reduce costul rețelei feed-forward, rezultând un model care este masiv, dar eficient.
Bugetul de 3 trilioane de token-uri este, de asemenea, demn de remarcat. Antrenarea unui model de această amploare necesită o cantitate uriașă de date și resurse de calcul. Faptul că MiniMax a reușit să aloce un astfel de buget demonstrează nu doar angajamentul lor față de această tehnologie, ci și încrederea că MSA va aduce beneficii semnificative. Rezultatele preliminare sugerează că MSA atinge performanțe comparabile cu atenția plină pe o gamă largă de benchmark-uri, în timp ce reduce costul computațional cu un factor semnificativ. Acest lucru deschide ușa către modele cu contexte mult mai lungi, capabile să proceseze documente întregi, cărți sau chiar baze de date masive într-o singură trecere.
Implicațiile acestei tehnologii sunt vaste. În primul rând, ar putea democratiza accesul la modele de limbaj puternice, permițând cercetătorilor și companiilor cu resurse limitate să antreneze și să ruleze modele mari. În al doilea rând, ar putea duce la dezvoltarea de aplicații noi care necesită înțelegerea unor contexte foarte lungi, cum ar fi analiza juridică a documentelor, sinteza literaturii științifice sau asistenții virtuali care pot urmări conversații complexe pe perioade îndelungate. În al treilea rând, MSA ar putea îmbunătăți eficiența energetică a antrenării și inferenței modelelor, contribuind la reducerea amprentei de carbon a AI-ului.
Desigur, există și provocări. Implementarea MSA necesită o inginerie atentă pentru a asigura că selecția token-urilor globale este optimă și că cele două ramuri sunt bine echilibrate. De asemenea, rămâne de văzut cum se va comporta MSA pe o gamă mai largă de sarcini și dacă va putea fi scalată la modele și mai mari. Cu toate acestea, direcția este clară: eficiența este cheia pentru viitorul AI-ului, iar MSA reprezintă un pas important în această direcție.
În concluzie, MiniMax Sparse Attention nu este doar o altă inovație tehnică; este o schimbare de paradigmă în modul în care gândim atenția în modelele de limbaj. Prin combinarea eficienței atenției dispersate cu puterea modelelor MoE, MSA deschide calea către modele mai mari, mai rapide și mai accesibile. Rămâne de văzut cum va fi adoptată această tehnologie, dar un lucru este cert: viitorul AI-ului va fi construit pe baza unor astfel de inovații.
De ce este important:
MiniMax Sparse Attention (MSA) este important deoarece abordează una dintre cele mai mari limitări ale modelelor de limbaj mari: costul computațional al atenției, care crește pătratic cu lungimea secvenței. Prin introducerea unei arhitecturi cu două ramuri care combină atenția locală și globală dispersată, MSA reduce dramatic acest cost, permițând modelelor să gestioneze contexte mult mai lungi fără a sacrifica performanța. Antrenată pe un model MoE de 109 miliarde de parametri cu un buget de 3 trilioane de token-uri, MSA demonstrează că eficiența și puterea pot merge mână în mână. Această inovație are potențialul de a democratiza accesul la AI-ul avansat, de a permite aplicații noi care necesită contexte lungi și de a reduce impactul energetic al antrenării modelelor. Pe scurt, MSA reprezintă un pas crucial către un AI mai eficient, mai accesibil și mai sustenabil.



