Subiect: #LLM

Revoluția în Inteligența Artificială: Startup-ul Subquadratic susține că a spart blocajul care ținea LLM-urile pe loc
Startup-ul Subquadratic susține că a inventat un LLM bazat pe atenție rară, de 56 de ori mai rapid și mult mai ieftin decât modelele actuale. Teste independente confirmă performanțe competitive, dar scepticismul persistă din cauza accesului limitat și a folosirii ponderilor dintr-un model preexistent.
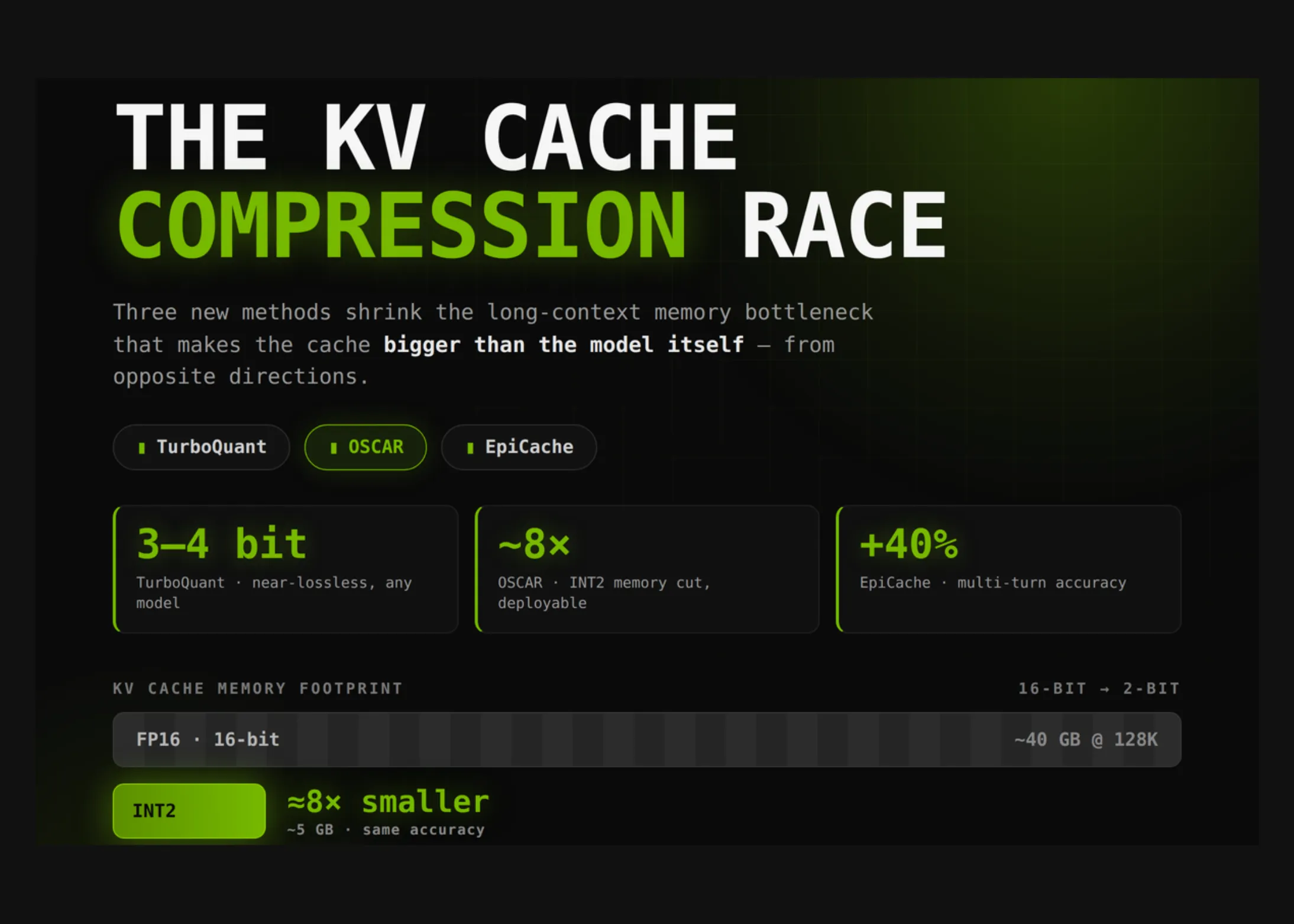
Cursa pentru compresia cache-ului KV: TurboQuant vs OSCAR vs EpiCache
TurboQuant, OSCAR și EpiCache sunt trei tehnologii de compresie a cache-ului KV care revoluționează modul în care rulează modelele de limbaj mari. Fiecare oferă un echilibru diferit între viteză, acuratețe și memorie, deschizând calea către un AI mai accesibil și mai eficient.
Ghid NVIDIA SkillSpector: Scanarea competențelor AI pentru riscuri de securitate cu analiză statică și rapoarte SARIF
Ghid complet pentru utilizarea NVIDIA SkillSpector în scanarea competențelor AI pentru riscuri de securitate. Include construirea unui corpus, analiză statică, organizare cu pandas, vizualizare, export SARIF și integrare CI/CD.
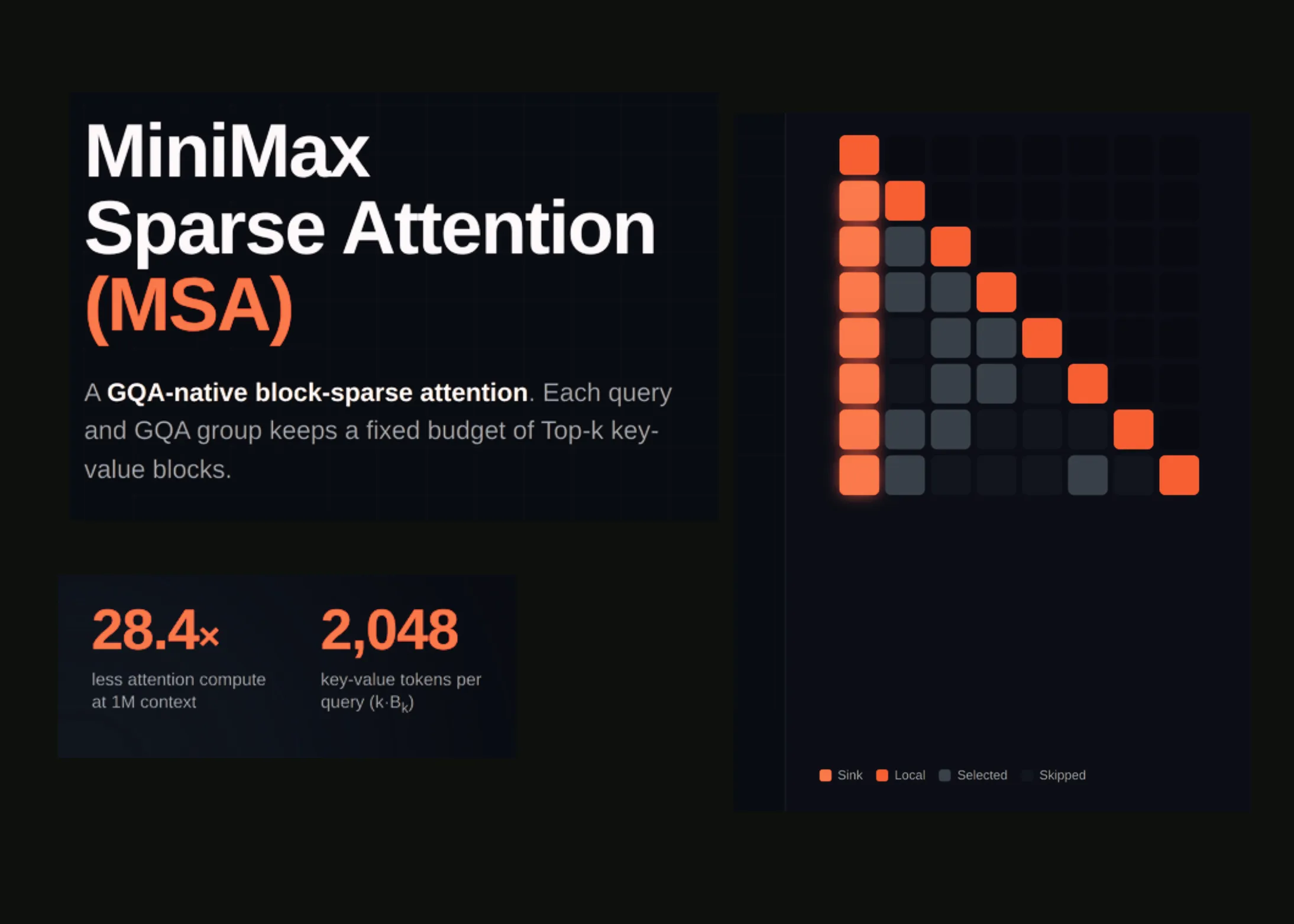
MiniMax Sparse Attention (MSA): O Revoluție în Atenția Dispersată cu Două Ramuri, Antrenată pe un Model MoE de 109 Miliarde de Parametri cu un Buget de 3 Tiloane de Token-uri
MiniMax Sparse Attention (MSA) este o arhitectură inovatoare de atenție dispersată cu două ramuri, antrenată pe un model MoE de 109 miliarde de parametri cu un buget de 3 trilioane de token-uri. MSA combină atenția locală și globală pentru a reduce costul computațional, permițând modelelor să gestioneze contexte mai lungi eficient. Această tehnologie ar putea democratiza accesul la AI și permite aplicații noi.
Implementare Cod pentru Microsoft SkillOpt: Optimizare Prompt Instrumentată, Analiză Evoluție Skill și Comparație cu Linia de Bază
Implementare practică a Microsoft SkillOpt pentru optimizarea prompturilor, incluzând configurarea, evaluarea liniei de bază, bucla de optimizare cu rollout, reflecție, agregare, selecție, actualizare și validare, plus analiza rezultatelor și comparația cu skill-ul original.

NVIDIA garak: Cum să construiești un flux complet de red-teaming defensiv pentru LLM-uri cu sonde și detectoare personalizate
Descoperă cum să folosești NVIDIA garak pentru a construi un workflow complet de red-teaming defensiv pentru LLM-uri, cu sonde și detectoare personalizate. Tutorial pas cu pas, de la instalare la analiza rezultatelor.

Revoluția prețurilor la GitHub Copilot: de ce plătesc acum dezvoltatorii mai mult pentru asistența AI
GitHub Copilot a trecut la facturarea pe bază de tokeni, ceea ce a dus la creșteri semnificative de costuri pentru dezvoltatori. Abonamentele au rămas la același preț, dar acum oferă un număr limitat de credite, consumate rapid în funcție de modelul AI utilizat. Reacțiile utilizatorilor variază de la șoc la resemnare, iar companiile trebuie să își regândească strategiile de adoptare a AI-ului.

Perplexity AI lansează open-source un tokenizer Unigram care reduce latența p50 de 5 ori față de crate-ul Hugging Face
Perplexity AI a lansat open-source un tokenizer Unigram care oferă o latență p50 de cinci ori mai mică decât Hugging Face tokenizers, promițând să accelereze procesarea textului în modelele de limbaj.

De ce inteligența artificială a Google nu poate scrie corect „Google” (sau orice alt cuvânt)
Google's AI Overview face greșeli de ortografie jenante, de la scrierea incorectă a propriului nume până la numărarea greșită a literelor. Articolul explică de ce modelele de limbaj mari nu pot ortografia corect, din cauza arhitecturii bazate pe tokeni, și subliniază importanța de a nu avea încredere oarbă în rezultatele AI.

EAGLE 3.1: Algoritmul de decodare speculativă care repară deriva atenției în inferența modelelor de limbaj
EAGLE 3.1 este un algoritm de decodare speculativă care corectează deriva atenției în inferența modelelor de limbaj, reducând latența cu până la 60% și menținând calitatea textului generat.

MEMO: Un cadru modular pentru antrenarea unui model de memorie dedicat pe cunoștințe noi, fără a modifica parametrii LLM
MEMO este un cadru modular care permite antrenarea unui model de memorie separat de LLM, facilitând actualizarea cunoștințelor fără a modifica parametrii originali. Aceasta reduce costurile, previne pierderea cunoștințelor și permite personalizarea, având potențialul de a revoluționa domeniul AI.

OpenRouter își dublează evaluarea la 1,3 miliarde de dolari într-un singur an
OpenRouter, un startup care oferă un gateway unificat pentru modele AI, a strâns 113 milioane de dolari într-o rundă Seria B, ajungând la o evaluare de 1,3 miliarde de dolari. Creșterea reflectă adoptarea tot mai mare a unei abordări multi-model în industrie.