Subiect: #LLM

Modelele lumii: Cheia pentru o inteligență artificială cu adevărat fiabilă
Modelele lumii (world models) sunt considerate cheia pentru a face inteligența artificială mai fiabilă, permițând sistemelor să înțeleagă și să simuleze mediul fizic, depășind limitările modelelor de limbaj mari (LLM-uri). Articolul explorează eforturile marilor companii (Google DeepMind, World Labs, OpenAI, Niantic) și potențialul acestor modele în robotică și aplicații practice.

OpenAI deschide codul sursă al Euphony: Un instrument de vizualizare bazat pe browser pentru datele Harmony Chat și jurnalurile sesiunilor Codex
OpenAI a deschis codul sursă al Euphony, un instrument de vizualizare bazat pe browser care permite analiza detaliată a datelor de interacțiune din Harmony Chat și jurnalelor sesiunilor Codex, promovând transparența și interpretabilitatea în AI.

De ce opinia despre AI este atât de împărțită: două realități, o singură tehnologie
AI Index 2026 de la Stanford revela o diferență de 50 de puncte procentuale între experții și publicul privind impactul AI asupra locurilor de muncă — o dovadă a existenței două realități parallele: una de excelență tehnică și una de limitări zilnice. Înțelegerea acestei dicotomii este esențială pentru a evita iluziile sau pessimismul excesiv și pentru a formula politici și investiții realiste în era AI.

Citizen Developerii au acum propriul lor Wingman: un agent autonom care transformă ideile în aplicații fără a necesita cunoștințe de programare
Wingman, agentul autonom lansat de Emergent, permite citizen developerilor — fara cunoștințe de programare — să creeze, gestioneze și automateze aplicații prin interacțiuni în limba naturală, cu limite de încredere și integrare fără cod cu WhatsApp, Telegram, CRM-uri și alte platforme zilnice, transformând ideile în software funcțional — dar ridicând și întrebări importante despre siguranță și menținere.
Traficul generat de inteligența artificială către retailerii americani a crescut cu 393% în primul trimestru din 2026, impulsionând totodată veniturile acestora
Traficul AI către retailerii americani a explodat cu 393% în T1 2026, iar vizitatorii generați de asistenții virtuali convertesc acum cu 42% mai bine decât clienții umani, inversând o tendință din urmă cu doar un an.
Cercetarea revoluționară Google DeepMind permite unui LLM să-și rescrie propriile algoritmi de teoria jocurilor — și i-a depășit pe experți
Google DeepMind a dezvoltat AlphaEvolve, un sistem AI capabil să-și rescrie autonom algoritmii de teoria jocurilor, demonstrând performanțe care depășesc expertiza umană în jocuri cu informație imperfectă precum poker.

Fostul insider de la Facebook care construiește moderarea conținutului pentru era AI
Brett Levenson, fostul lider de integritate de la Facebook, a fondat Moonbounce pentru a revoluționa moderarea conținutului în era inteligenței artificiale, transformând documentele de politică în cod executabil și oferind răspunsuri în timp real.

Trecerea la personalizarea modelelor AI: o cerință arhitecturală strategică
Pe măsură ce scalarea LLM-urilor atinge randamente descrescătoare, organizațiile trebuie să treacă de la modele generaliste la cele personalizate pe domeniu. Institutuționalizarea logicii proprietare în AI reprezintă noul șanț competitiv strategic.

Kimina-Prover: Revoluția în Demonstrația Automată de Teoreme prin Căutare RL în Timpul Testării
Kimina-Prover-72B stabilește un nou standard în demonstrația automată de teoreme, atingând o rată de succes de 92.2% pe benchmark-ul miniF2F. Inovația sa principală, cadrul TTRL Search, permite modelului să descopere și combine recursiv leme, transformând procesul dintr-o simplă generare într-o căutare agentică strategică și profundă.

Cinci îmbunătățiri majore aduse serverelor Gradio MCP: Suport fișiere locale, notificări în timp real și integrare API automatizată
Versiunea Gradio 5.38.0 aduce cinci inovații majore pentru serverele MCP: suport automat pentru încărcarea fișierelor locale, notificări de progres în timp real, transformarea specificațiilor OpenAPI în servere MCP printr-o singură linie de cod, îmbunătățiri ale autentificării prin header-e și posibilitatea personalizării descrierilor instrumentelor.
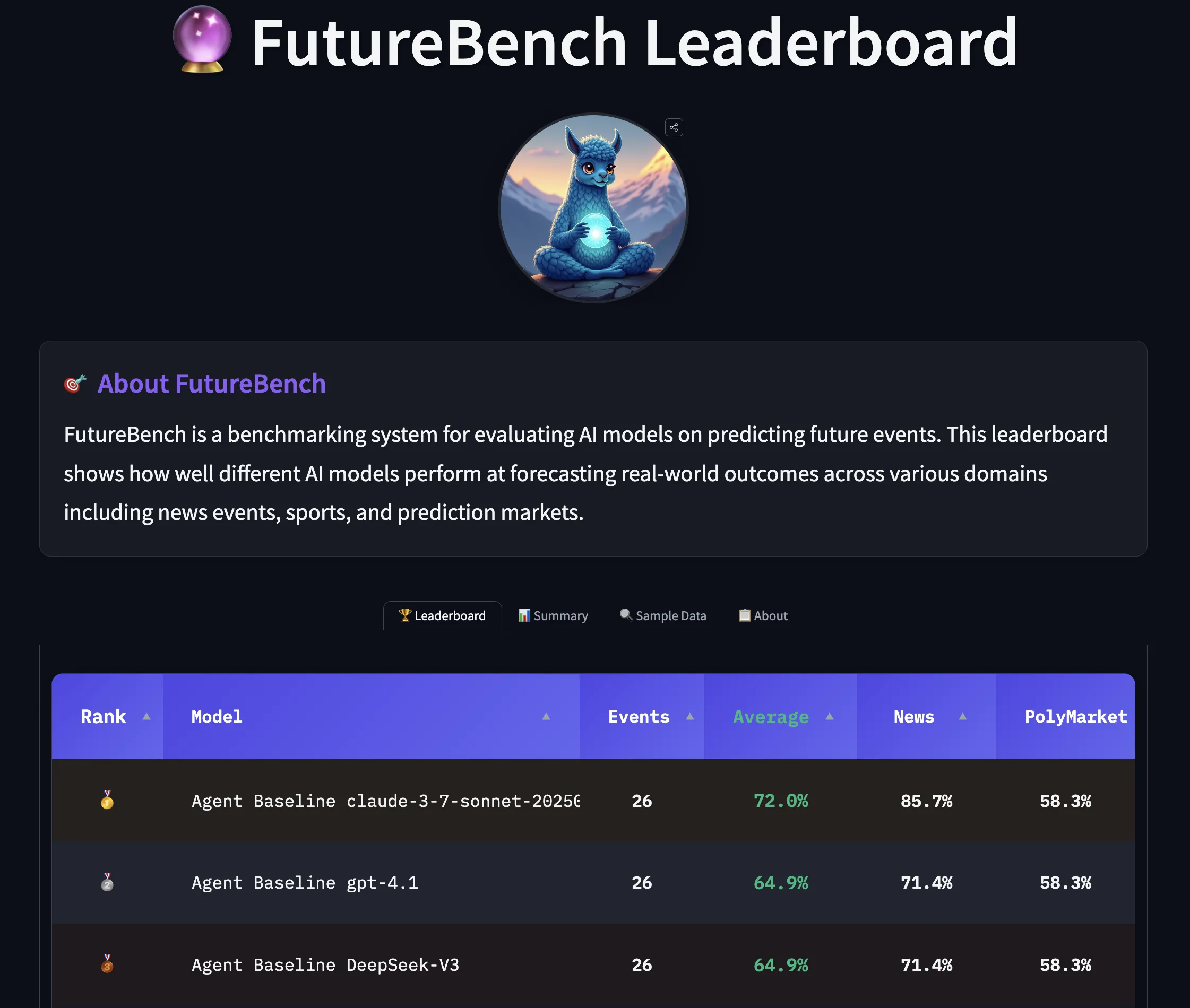
Înapoi în Viitor: Evaluarea Agenților AI în Predicția Evenimentelor Viitoare
Un nou benchmark revoluționar, FutureBench, propune evaluarea agenților AI pe baza capacității lor de a prezice evenimente viitoare, trecând de la testarea memorării faptelor istorice la măsurarea raționamentului complex și a înțelegerii cauzale.
Consilium: Când modelele de limbaj colaborează – O revoluție în inteligența artificială distribuită
Consilium reprezintă o platformă revoluționară care permite multiplelor modele de limbaj mari (LLM) să colaboreze și să discute pentru a atinge consensuri, depășind limitările analizei individuale și validată de cercetări recente care arată că sistemele multi-AI pot atinge 85.5% acuratețe în diagnostic medical comparativ cu doar 20% pentru medicii umani.