Subiect: #Eficiență Computațională
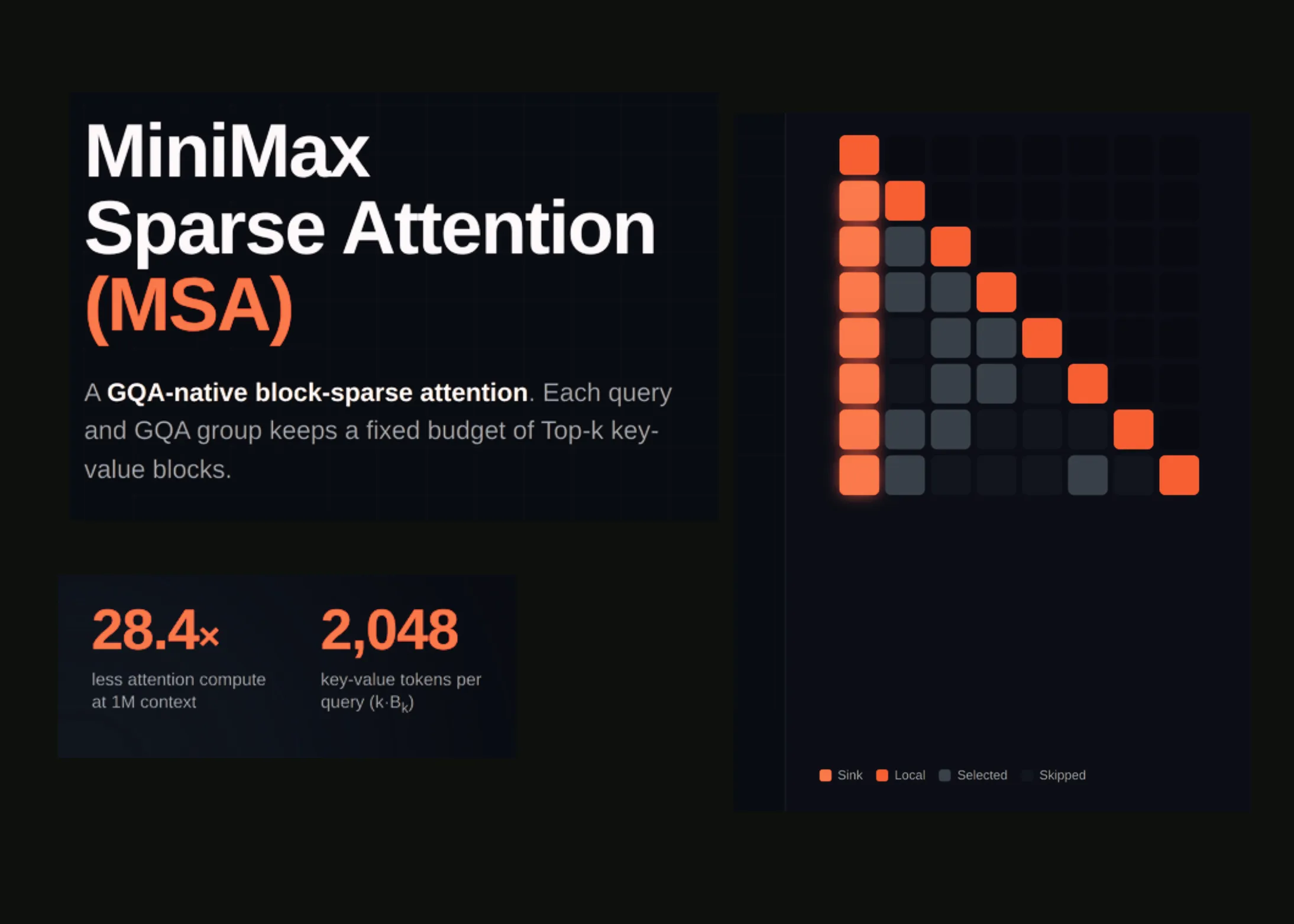
MiniMax Sparse Attention (MSA): O Revoluție în Atenția Dispersată cu Două Ramuri, Antrenată pe un Model MoE de 109 Miliarde de Parametri cu un Buget de 3 Tiloane de Token-uri
MiniMax Sparse Attention (MSA) este o arhitectură inovatoare de atenție dispersată cu două ramuri, antrenată pe un model MoE de 109 miliarde de parametri cu un buget de 3 trilioane de token-uri. MSA combină atenția locală și globală pentru a reduce costul computațional, permițând modelelor să gestioneze contexte mai lungi eficient. Această tehnologie ar putea democratiza accesul la AI și permite aplicații noi.

Trajectory lansează un stack de antrenament Multi-LoRA concurent pentru învățare continuă, raportând un câștig de 2,81× în debitul experimentelor
Trajectory a lansat un stack de antrenament Multi-LoRA concurent care permite rularea simultană a mai multor experimente, raportând un câștig de 2,81× în debit. Aceasta optimizează utilizarea memoriei și a GPU-urilor, facilitând învățarea continuă fără pierderea performanței pe sarcinile anterioare.

Cohere lansează Command A+: Un model MoE de 218B parametri pentru fluxuri de lucru agentice, care rulează pe doar două GPU-uri H100
Cohere lansează Command A+, un model de 218 miliarde de parametri cu arhitectură Mixture of Experts, capabil să ruleze pe doar două GPU-uri H100. Modelul este optimizat pentru fluxuri de lucru agentice, stabilind noi recorduri de performanță și democratizând accesul la AI avansat.

Nous Research revoluționează antrenarea modelelor lingvistice: Token Superposition Training reduce timpul de pre-antrenare de până la 2,5 ori
Nous Research lansează Token Superposition Training (TST), o metodă de pre-antrenare în două faze care reduce timpul de antrenare al modelelor lingvistice de mari dimensiuni cu până la 2,5 ori, fără a modifica arhitectura sau performanța la inferență. Validată pe modele de la 270M la 10B parametri, TST promite să democratizeze accesul la antrenarea LLM-urilor.

Apriel-H1: Cheia surprinzătoare pentru distilarea modelelor eficiente de raționament
Descoperă cum Apriel-H1 redefinește eficiența modelelor de raționament prin distilare hibridă, înlocuind straturile de atenție cu Mamba și obținând o creștere a vitezei de 2.1x fără a compromite calitatea gândirii logice.