Domeniu: AI

Nu trebuie să fii o startup AI pentru a atrage finanțare. Lucra demonstrează acest lucru cu 20 de milioane de dolari
Lucra, o platformă de gamificare a loialității pentru sporturi sociale, a strâns 20 de milioane de dolari de la ARK Invest fără a se baza pe AI. Povestea demonstrează că autenticitatea și execuția solidă pot atrage finanțare chiar și într-o piață dominată de hype-ul inteligenței artificiale.

Sam Altman face o ofertă spectaculoasă: 2 milioane de dolari în tokeni OpenAI pentru fiecare startup Y Combinator
Sam Altman oferă fiecărui startup din actualul batch Y Combinator tokeni OpenAI în valoare de 2 milioane de dolari, în schimbul unei participații la capital printr-un SAFE fără plafon. Oferta stârnește dezbateri: ajută startup-urile să reducă costurile AI, dar le expune riscului de a fi copiate de OpenAI.

Dosarul IPO SpaceX a fost făcut public: ce dezvăluie documentele despre gigantul spațial al lui Elon Musk
SpaceX a făcut public dosarul pentru IPO, dezvăluind pierderi de 4,9 miliarde de dolari în 2025, venituri de peste 18 miliarde și o dependență majoră de Starlink și Starship. Divizia de AI a companiei, xAI, consumă 60% din cheltuielile de capital, dar pierde miliarde. IPO-ul, estimat la 75 de miliarde de dolari, ar putea fi cel mai mare din istorie.

OpenAI susține că a rezolvat o problemă matematică veche de 80 de ani – de data aceasta, pe bune
OpenAI susține că noul său model de raționament a demonstrat o conjectură geometrică veche de 80 de ani, infirmând credințele matematicienilor. De data aceasta, compania a publicat și comentarii de sprijin din partea unor experți, spre deosebire de o afirmație falsă anterioară.

IrisGo: asistentul AI de birou pe care nu știai că ți-l dorești, susținut de Andrew Ng
IrisGo, startup susținut de Andrew Ng, dezvoltă un asistent desktop AI care învață fluxurile de lucru ale utilizatorilor și le automatizează. Cu o rundă seed de 2,8 milioane de dolari și parteneriate cu Acer, Nvidia și Google, IrisGo vizează automatizarea sarcinilor repetitive pentru lucrătorii de birou, punând accent pe confidențialitatea datelor prin procesare locală.

OpenAI se îndreaptă spre o ofertă publică inițială care ar putea avea loc în septembrie
OpenAI se pregătește pentru un IPO în septembrie, concurând cu SpaceX al lui Elon Musk. După pierderea procesului, Musk și Altman își mută rivalitatea pe Wall Street. Articolul analizează implicațiile financiare și strategice ale acestor listări.

Cum să construiești pipeline-uri de generare a grafurilor de cunoștințe din text cu kg-gen, analize NetworkX și vizualizări interactive
Învață cum să construiești un pipeline complet de generare a grafurilor de cunoștințe din text folosind kg-gen, NetworkX și vizualizări interactive. De la extragerea entităților la analiza rețelei și crearea de grafuri dinamice, acest ghid practic îți arată pașii esențiali pentru a transforma textul nestructurat într-o resursă structurată și vizuală.

Meta concediază 8.000 de angajați și accelerează tranziția către inteligența artificială
Meta concediază 8.000 de angajați și mută alți 7.000 în echipe de AI, într-o reorganizare masivă menită să accelereze tranziția către inteligența artificială, în timp ce compania se confruntă cu pierderi în instanță și cu o concurență acerbă din partea OpenAI și Google.

Startup Battlefield 200: Ultima săptămână pentru înscrieri – Oportunitatea care a lansat Dropbox, Cloudflare și Discord se închide pe 27 mai
Startup Battlefield 200, competiția TechCrunch care a lansat Dropbox, Cloudflare și Discord, își închide înscrierile pe 27 mai. Află cum poți aplica pentru șansa de a prezenta la TechCrunch Disrupt 2026, de a câștiga 100.000 de dolari fără diluare și de a beneficia de expunere globală.

OpenAI se îndreaptă spre o ofertă publică inițială care ar putea avea loc în septembrie
OpenAI se pregătește pentru un IPO în septembrie, după ce Elon Musk a pierdut procesul împotriva companiei. Colaborarea cu Goldman Sachs și Morgan Stanley sugerează o ofertă masivă, iar competiția cu SpaceX se mută pe piața financiară.
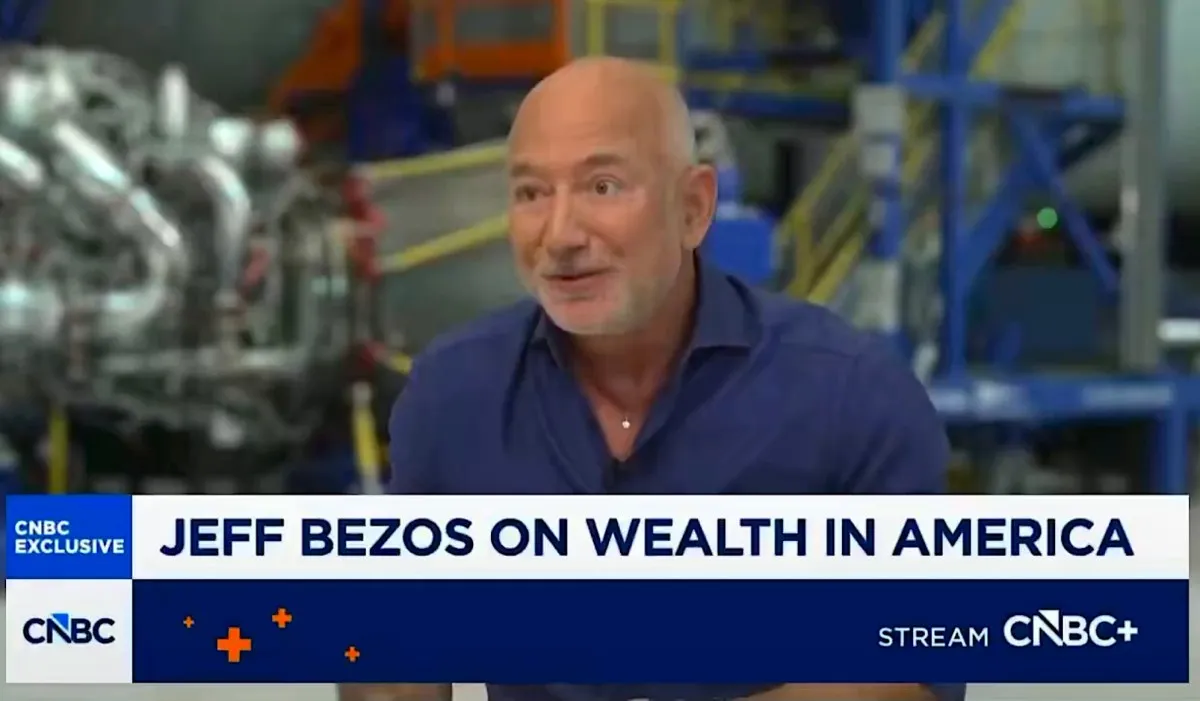
Jeff Bezos, ai fost atât de aproape să spui ceva corect
Jeff Bezos a declarat că americanii din jumătatea inferioară a veniturilor nu ar trebui să plătească taxe, dar el însuși plătește o rată de impozitare mult mai mică datorită lacunelor fiscale. Articolul analizează ipocrizia din spatele declarațiilor sale și dezbate dacă taxarea mai mare a miliardarilor ar putea ajuta cu adevărat clasa de mijloc.

Stability AI lansează un nou model audio capabil să creeze piese muzicale de șase minute
Stability AI lansează Stability Audio 3.0, o familie de modele audio capabile să genereze muzică de până la șase minute. Modelele mici și medii sunt open-source, iar cel mare este disponibil prin API. Compania a încheiat parteneriate cu Warner și Universal pentru licențierea datelor.