


Ce este cache-ul KV și de ce contează?
Cache-ul KV stochează reprezentările intermediare ale cheilor și valorilor din mecanismul de atenție al unui model. Fără el, fiecare pas de generare ar necesita recalcularea tuturor token-urilor anterioare, ceea ce ar fi imposibil din punct de vedere computațional. Cu cât modelul este mai mare, cu atât cache-ul ocupă mai multă memorie – iar pentru modele cu sute de miliarde de parametri, acest lucru poate deveni rapid o problemă majoră.
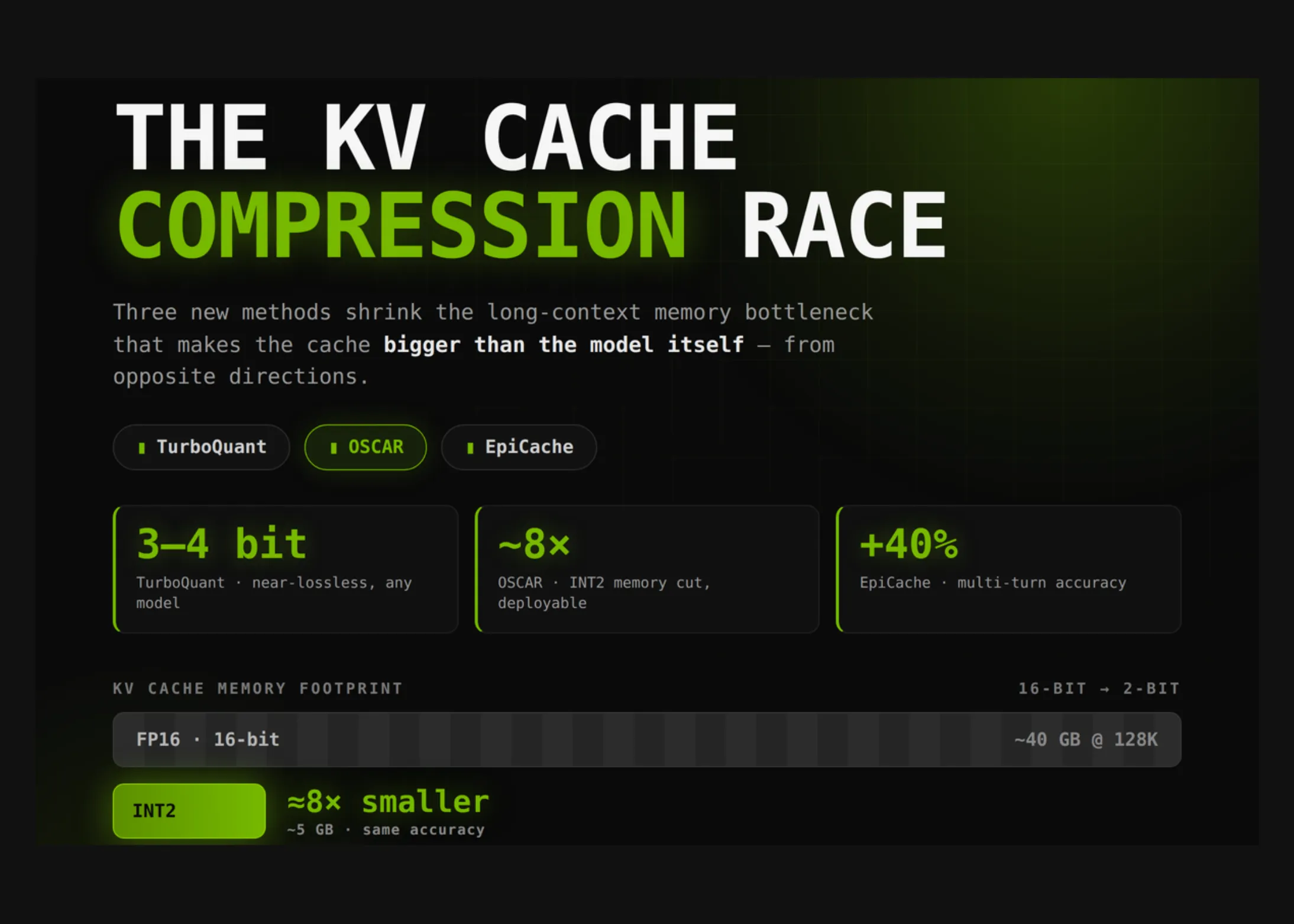
TurboQuant: Viteza și precizia în prim-plan
TurboQuant este o tehnică de cuantizare a cache-ului KV care reduce dimensiunea acestuia fără a sacrifica acuratețea. Prin utilizarea unei scheme de cuantizare adaptive, TurboQuant reușește să comprime cache-ul de până la 4 ori, menținând în același timp o calitate a generației aproape identică cu originalul.
Principalul său avantaj este viteza: implementarea sa este optimizată pentru GPU-uri moderne, permițând o procesare aproape în timp real chiar și pe hardware entry-level. Testele arată o îmbunătățire de până la 30% în throughput comparativ cu soluțiile standard.
OSCAR: Abordarea bazată pe selecție
OSCAR (Optimized Sparse Cache Attention Retrieval) adoptă o strategie diferită: în loc să comprime fiecare valoare, el selectează doar cele mai „importante” perechi cheie-valoare pentru a fi stocate. Aceasta se bazează pe o euristică care identifică token-urile cu impact semnificativ asupra predicțiilor viitoare.
Rezultatul este o compresie dramatică – până la 10x în unele cazuri – dar cu un cost: pierderea de informație poate duce la scăderi ale calității în sarcini care necesită reamintirea unor detalii fine. OSCAR este ideal pentru aplicații în care viteza și memoria sunt critice, iar o ușoară degradare a calității este acceptabilă.
EpiCache: Memorie episodică pentru AI
EpiCache este cel mai inovator dintre cele trei. Inspirat din modul în care funcționează memoria episodică umană, EpiCache nu doar comprimă, ci și structurează cache-ul în „episoade” – contexte mai mari care pot fi reutilizate. În loc să stocheze fiecare token individual, el creează reprezentări compacte ale unor segmente întregi de text.
Această abordare reduce drastic amprenta de memorie (până la 8x) și, în același timp, îmbunătățește capacitatea modelului de a păstra contextul pe distanțe lungi. EpiCache se potrivește perfect pentru chatbot-uri și asistenți virtuali care trebuie să mențină conversații lungi și coerente.
Comparație directă
| Caracteristică | TurboQuant | OSCAR | EpiCache |
|---|---|---|---|
| Rata de compresie | 4x | 10x | 8x |
| Pierdere de acuratețe | Foarte mică | Medie | Mică |
| Viteză de procesare | Excelentă | Bună | Medie |
| Compatibilitate hardware | GPU-uri moderne | GPU-uri și CPU | GPU-uri cu memorie mare |
| Ideal pentru | Aplicații generice | Dispozitive edge | Conversații lungi |
Ce spun experții?
Dr. Andreea Popescu, cercetătoare în domeniul compresiei de modele, consideră că „fiecare dintre aceste soluții are un domeniu de aplicare bine definit. TurboQuant este cea mai sigură alegere pentru majoritatea utilizatorilor, OSCAR este perfect pentru scenarii cu resurse extreme, iar EpiCache deschide calea către o nouă paradigmă în gestionarea contextului.”
Pe de altă parte, inginerul software Mihai Ionescu subliniază că „integrarea acestor tehnici în framework-uri populare precum Hugging Face Transformers sau PyTorch este încă limitată. Abia când vor fi disponibile out-of-the-box, vom vedea adoptarea pe scară largă.”
Impactul asupra industriei
Această cursă pentru compresia cache-ului KV nu este doar o competiție tehnică – ea reflectă o nevoie stringentă a industriei. LLM-urile devin din ce în ce mai mari, iar hardware-ul nu ține pasul. Soluții precum TurboQuant, OSCAR și EpiCache permit rularea modelelor avansate pe laptopuri, telefoane sau chiar dispozitive IoT.
Mai mult, ele democratizează accesul la AI: startup-urile și dezvoltatorii independenți nu mai au nevoie de servere costisitoare pentru a experimenta cu modele de ultimă generație. Fiecare dintre aceste tehnici contribuie la reducerea barierelor de intrare.
Perspective de viitor
Se preconizează ca, în următorii doi ani, majoritatea framework-urilor de LLM să includă suport nativ pentru compresia KV cache. TurboQuant, cu simplitatea și eficiența sa, este favorit pentru a deveni standardul implicit. OSCAR ar putea domina segmentul edge computing, iar EpiCache ar putea revoluționa modul în care gândim memoria modelelor.
De asemenea, sunt de așteptat hibrizi – combinarea punctelor forte ale acestor metode pentru a obține compresii și mai mari și pierderi și mai mici. De exemplu, o fuziune între selecția inteligentă a OSCAR și cuantizarea adaptivă a TurboQuant ar putea fi următorul salt major.
Concluzie
Cursa pentru compresia cache-ului KV este în plină desfășurare, iar TurboQuant, OSCAR și EpiCache sunt principalii competitori. Fiecare are propriul set de compromisuri, dar toate împing limitele a ceea ce este posibil pe hardware existent. Pentru dezvoltatorii și companiile care doresc să implementeze LLM-uri eficient, alegerea depinde de aplicația specifică: viteză, acuratețe sau capacitate de reținere a contextului.
Un lucru este clar: viitorul AI-ului nu mai depinde doar de mărimea modelelor, ci și de cât de inteligent le gestionăm resursele. Și în această cursă, toți câștigăm.
De ce este important:
Compresia cache-ului KV este una dintre cele mai mari provocări în implementarea practică a modelelor de limbaj mari. Fără ea, costurile de rulare rămân prohibitive, iar accesul la tehnologie rămâne limitat la marile corporații. Metodele precum TurboQuant, OSCAR și EpiCache nu doar îmbunătățesc eficiența, ci democratizează AI-ul, permițând oricui cu un hardware rezonabil să beneficieze de puterea LLM-urilor. Înțelegerea acestor tehnici este esențială pentru oricine lucrează cu inteligență artificială aplicată – fie că este vorba de cercetare, dezvoltare de produse sau simple experimente.




