Cercetătorii susțin că o inteligență artificială cu adevărat valoroasă, și în cele din urmă o Inteligență Generală Artificială (AGI), se va distinge prin capacitatea sa de a utiliza trecutul pentru a previzui aspecte interesante ale viitorului, mai degrabă decât să recite simplu fapte vechi. Această viziune stă la baza unui nou proiect de evaluare denumit FutureBench, care își propune să testeze limitele raționamentului AI într-un mod complet nou.
Complexitatea predicției: Mai mult decât recunoașterea tiparelor
Prezicerea evenimentelor viitoare reprezintă o sarcină complexă și holistică, care necesită un nivel superior de sofisticare cognitivă. Spre deosebire de răspunsurile bazate pe date istorice, predicția cere un raționament elaborat, sinteza informațiilor din surse multiple, cântărirea probabilităților și o înțelegere genuină a cauzalității, evitând simpla potrivire a tiparelor sau căutarea informațiilor deja existente. Evaluarea modelelor pe capacitatea lor de a prezice rezultate viitoare – fie că vorbim despre știință, economie, geopolitică sau tehnologie – testează exact acel tip de inteligență care creează valoare reală în lume.
Mai mult decât atât, această abordare bazată pe predicție rezolvă o problemă metodologică majoră cu care se confruntă evaluările actuale. Benchmark-urile tradiționale care măsoară acuratețea pe seturi de test fixe sunt inevitabil afectate de riscul contaminării datelor. Fără acces la întregul pipeline de antrenament reproductibil al unui model, este dificil să ai încredere deplină în rezultate. Cele mai serioase eforturi de evaluare păstrează acum seturile de test complet private, creând o cursă a înarmării frustrantă între evaluatori și mecanismele de „trickery” ale clasamentelor. Predicția face contaminarea imposibilă prin design, pur și simplu pentru că nu poți antrena un model pe date care nu există încă. Acest lucru creează un teren de joacă echitabil, unde succesul depinde de capacitatea de raționament, nu de memorare.
FutureBench: O arhitectură inovatoare pentru testarea viitorului
FutureBench extrage evenimente din piețele reale de predicție și din știrile emergente pentru a crea sarcini de predicție interesante, ancorate în rezultate viitoare reale. Cercetătorii colectează evenimente de pe platforme precum Polymarket și din acoperirea media live, filtrându-le pentru a se concentra pe evenimente emergente care merită să fie prezise. Folosind o abordare bazată pe agenți, echipa curatează scenarii care necesită raționament autentic.
Pentru a construi un benchmark care să testeze capacități reale de predicție, a fost nevoie de un flux constant de întrebări semnificative. S-au dezvoltat două abordări complementare care capturează diferite tipuri de evenimente viitoare:
1. Întrebări generate din știri: Găsirea titlurilor de mâine astăzi
Prima abordare utilizează AI pentru a extrage evenimente curente și a le transforma în oportunități de predicție. Un agent bazat pe framework-ul smolagents este utilizat pentru a extrage date de pe câteva site-uri majore de știri, pentru a analiza articolele de pe prima pagină și pentru a genera întrebări de predicție despre rezultatele lor probabile. Agentul citește și identifică articole interesante, formulând întrebări specifice și limitate în timp. De exemplu: „Va reduce Rezerva Federală dobânzile cu cel puțin 0,25% până la 1 iulie 2025?”. Acest proces este ghidat de prompt-uri atent elaborate care specifică ce face ca o întrebare de predicție să fie bună – evenimente care sunt semnificative, verificabile și incerte la momentul extragerii. Agentul generează de obicei 5 întrebări pe sesiune, cu un orizont de timp de o singură săptămână.
2. Integrarea Polymarket: Valorificarea piețelor de predicție
A doua sursă provine din Polymarket, o platformă de piață de predicție unde participanți reali fac prognoze despre evenimente viitoare. În prezent, sunt preluate aproximativ 8 întrebări pe săptămână. Totuși, datele brute necesită filtrare. Se aplică filtre puternice pentru a elimina întrebările generale despre temperatură și unele întrebări despre piețele bursiere și criptomonede, care ar fi altfel prea numeroase pentru utilizarea practică în benchmark. În plus, întrebările din Polymarket au mai puține constrângeri privind timpul final de „realizare”, rezultatul efectiv al evenimentului putând fi disponibil doar luna viitoare sau la sfârșitul anului.
Exemple de întrebări și scenarii testate
Pentru a ilustra concret cum arată acest benchmark, iată câteva exemple din pipeline-ul de generare a întrebări:
Din categoria știrilor generate: „Va crește inflația lunară cu 0,2% în iunie?” sau „Vor avea loc Ucraina și Rusia negocieri de pace până la 8 iulie 2025?”. Din categoria Polymarket: „Va fi marja de victorie RCV a lui Zohran Mamdani mai mare de 13% în alegerile primare democratice pentru primăria New York City?”. Aceste exemple demonstrează diversitatea și relevanța evenimentelor monitorizate.
Un cadru sistematic de evaluare pe trei niveluri
FutureBench nu se limitează la a pune întrebări; oferă un cadru metodologic riguros pentru a înțelege exact ce se măsoară. Framework-ul operează pe trei niveluri distincte:
Această abordare sistematică permite înțelegerea exactă a locului unde apar câștigurile și pierderile de performanță în pipeline-ul agentului. Benchmark-ul servește și ca un test robust al capacității de a urma instrucțiuni, agenții trebuind să respecte cerințe specifice de formatare.
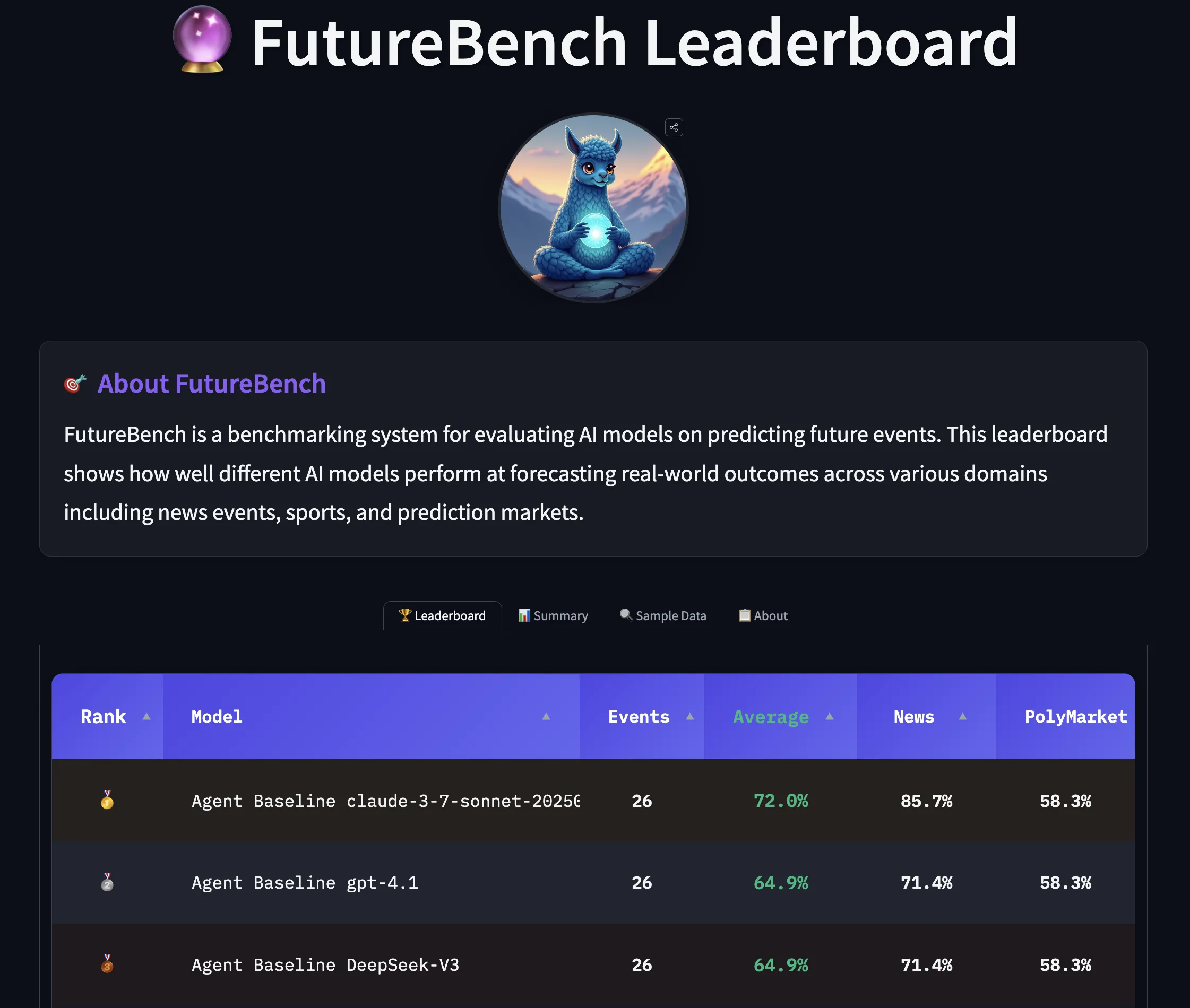
Rezultate inițiale și tipare de acțiune interesante
În testele preliminare, s-a utilizat SmolAgents ca framework de bază pentru toate întrebările. Așa cum era de așteptat, modelele agentice au performat mai bine decât modelele de limbaj simple, iar modelele mai puternice au arătat o calitate a predicției mai stabilă. Totuși, au apărut tipare fascinante în modul în care diferite modele abordează colectarea informațiilor.
O diferență izbitoare a fost observată în ceea ce privește scraping-ul web. GPT-4.1 pare să se bazeze mai mult pe rezultatele căutării directe. În schimb, modelele Claude 3.7 și 4 explorează spațiul web în mai mare detaliu și tind să utilizeze scraping-ul web mai frecvent. Această abordare temeinică înseamnă colectarea unui număr mult mai mare de token-i de intrare în timpul procesului de cercetare, crescând astfel costul operațional. Modelele arată abordări interesante și în formularea predicțiilor, demonstrând că nu există o singură cale către „viitor” în lumea inteligenței artificiale.
Această cercetare deschide noi orizonturi în evaluarea AI, sugerând că viitorul benchmark-urilor nu stă în testarea a ceea ce modelele știu, ci în testarea a ceea ce pot deduce despre lumea care urmează să vină.