Subiect: #Raționament

VibeThinker-3B: Modelul de raționament dens de 3B parametri construit pe Qwen2.5-Coder-3B cu pipeline-ul Spectrum-to-Signal
VibeThinker-3B este un model dens de raționament de 3 miliarde de parametri, construit pe Qwen2.5-Coder-3B și antrenat cu pipeline-ul Spectrum-to-Signal. Oferă performanțe apropiate de modelele de 7B, fiind open-source și accesibil pe hardware modest.
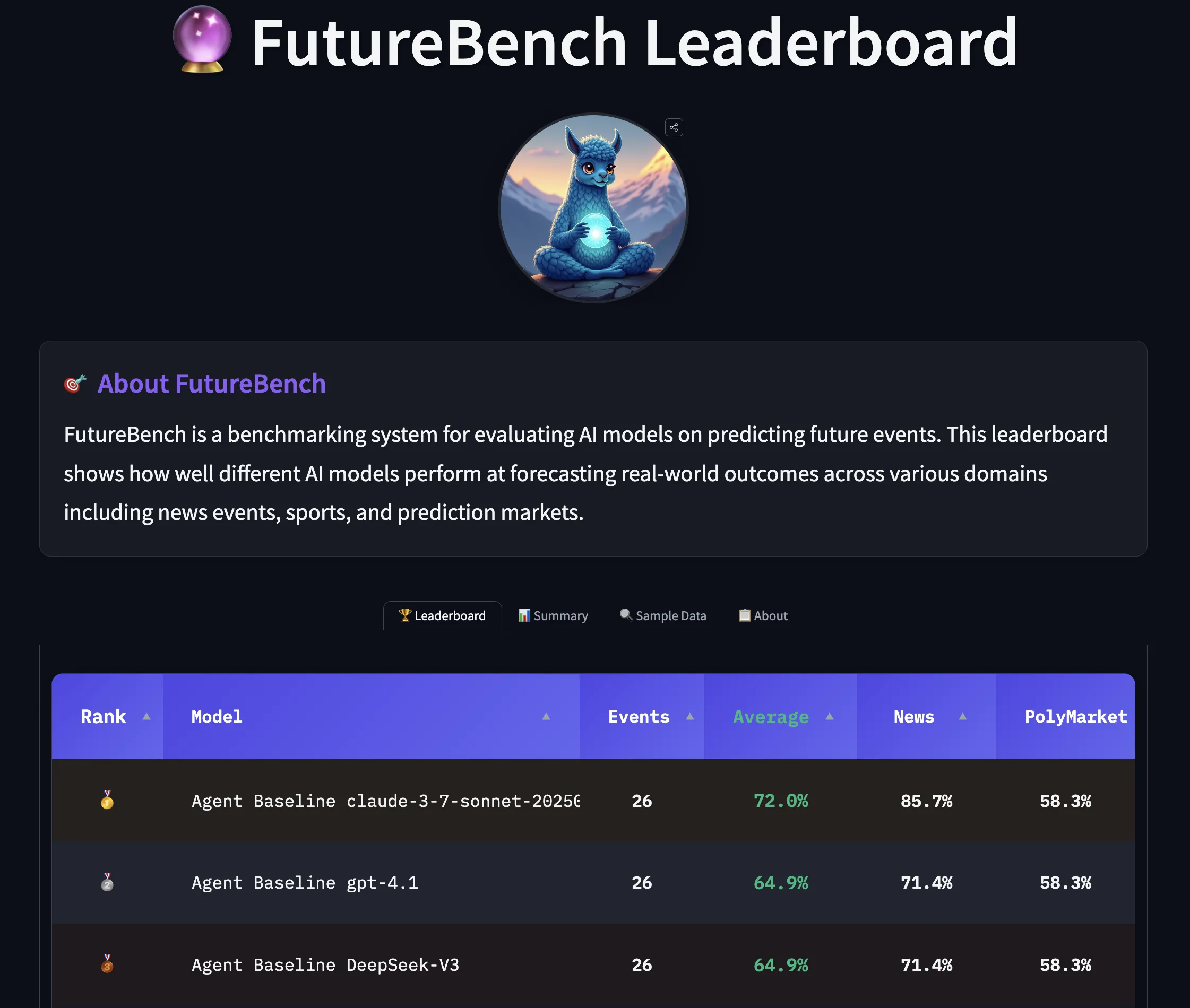
Înapoi în Viitor: Evaluarea Agenților AI în Predicția Evenimentelor Viitoare
Un nou benchmark revoluționar, FutureBench, propune evaluarea agenților AI pe baza capacității lor de a prezice evenimente viitoare, trecând de la testarea memorării faptelor istorice la măsurarea raționamentului complex și a înțelegerii cauzale.
TextQuests: Cât de performante sunt modelele lingvistice mari în jocurile video textuale?
TextQuests este un nou benchmark bazat pe 25 de jocuri clasice de ficțiune interactivă, menit să evalueze capacitatea modelelor lingvistice mari de a raționa pe termen lung și de a învăța prin explorare, relevând dificultăți semnificative în raționamentul spațial și gestionarea contextului extins.