


Ce este LFM2.5-230M și de ce contează?
LFM2.5-230M face parte din familia Liquid Foundation Models, dezvoltată de startup-ul american Liquid AI, fondat de cercetători care au lucrat la MIT și au contribuit la teoria rețelelor neuronale lichide. Spre deosebire de modelele masive de tip GPT sau Llama, care necesită resurse uriașe de calcul și memorie, LFM2.5-230M are doar 230 de milioane de parametri. Asta înseamnă că poate fi rulat pe un laptop obișnuit, pe un telefon sau chiar pe un Raspberry Pi, fără să sacrifice prea mult din calitatea răspunsurilor.
Ce face acest model special? Arhitectura sa lichidă – o abordare inovatoare care permite adaptabilitate dinamică la datele de intrare, fără a necesita reantrenare completă. În termeni simpli, modelul „curge” și se ajustează în timp real, oferind răspunsuri mai precise și mai coerente decât modelele statice de aceeași dimensiune. Iar acum, cu suportul pentru cinci motoare de inferență, devine și mai accesibil.
Suportul pentru llama.cpp – performanță pe CPU
llama.cpp este, fără îndoială, unul dintre cele mai populare framework-uri pentru rularea modelelor de limbaj pe hardware modest. Scris în C++ și optimizat pentru CPU, permite cuantizarea modelelor și rularea lor chiar și pe procesoare fără GPU. LFM2.5-230M integrat cu llama.cpp înseamnă că oricine are un laptop cu un procesor modern poate rula un model AI conversațional fără să trimită date în cloud. Pentru utilizatorii preocupați de confidențialitate, asta e o veste excelentă.
MLX – puterea Apple Silicon
MLX este framework-ul open-source dezvoltat de Apple pentru a profita la maximum de cipurile M1, M2, M3 și M4. Suportul pentru MLX înseamnă că LFM2.5-230M poate rula nativ pe Mac-uri și iPad-uri cu Apple Silicon, folosind accelerarea hardware oferită de Neural Engine. Testele preliminare arată că modelul rulează fluid chiar și pe un MacBook Air cu 8 GB RAM, ceea ce deschide ușa către aplicații AI locale pe dispozitivele Apple fără a fi nevoie de o conexiune la internet.
vLLM și SGLang – pentru servere și aplicații enterprise
Pentru cei care au nevoie de performanță maximă în medii server, vLLM și SGLang sunt soluțiile ideale. vLLM este cunoscut pentru gestionarea eficientă a memoriei și a concurenței, permițând servirea mai multor cereri simultan cu latență scăzută. SGLang, pe de altă parte, oferă un sistem de programare structurată a interacțiunilor cu modelul, ideal pentru aplicații complexe de tip agent AI. LFM2.5-230M suportă ambele, ceea ce îl face potrivit atât pentru prototipuri rapide, cât și pentru implementări la scară largă.
ONNX – portabilitate universală
ONNX (Open Neural Network Exchange) este standardul deschis pentru interoperabilitatea modelelor de machine learning. Suportul ONNX înseamnă că LFM2.5-230M poate fi exportat și rulat pe orice platformă care suportă acest format – de la Windows la Linux, de la edge devices la cloud. Practic, dacă ai un mediu de rulare care acceptă ONNX, poți integra acest model fără bătăi de cap.
Implicații pentru dezvoltatori și utilizatori
Lansarea LFM2.5-230M cu acest suport extins nu este doar o simplă actualizare tehnică. Este un pas important spre democratizarea AI-ului. Până acum, modelele performante erau fie prea mari pentru a rula local, fie necesitau framework-uri proprietare. Liquid AI a ales să meargă pe calea open-source și a compatibilității maxime.
Pentru dezvoltatori, asta înseamnă că pot integra un model AI în aplicațiile lor mobile, desktop sau web fără să depindă de API-uri externe. Costurile scad, latența dispare, iar confidențialitatea datelor rămâne intactă. Pentru utilizatorii finali, înseamnă aplicații mai rapide, mai sigure și care funcționează chiar și offline.
Cum se compară cu alte modele?
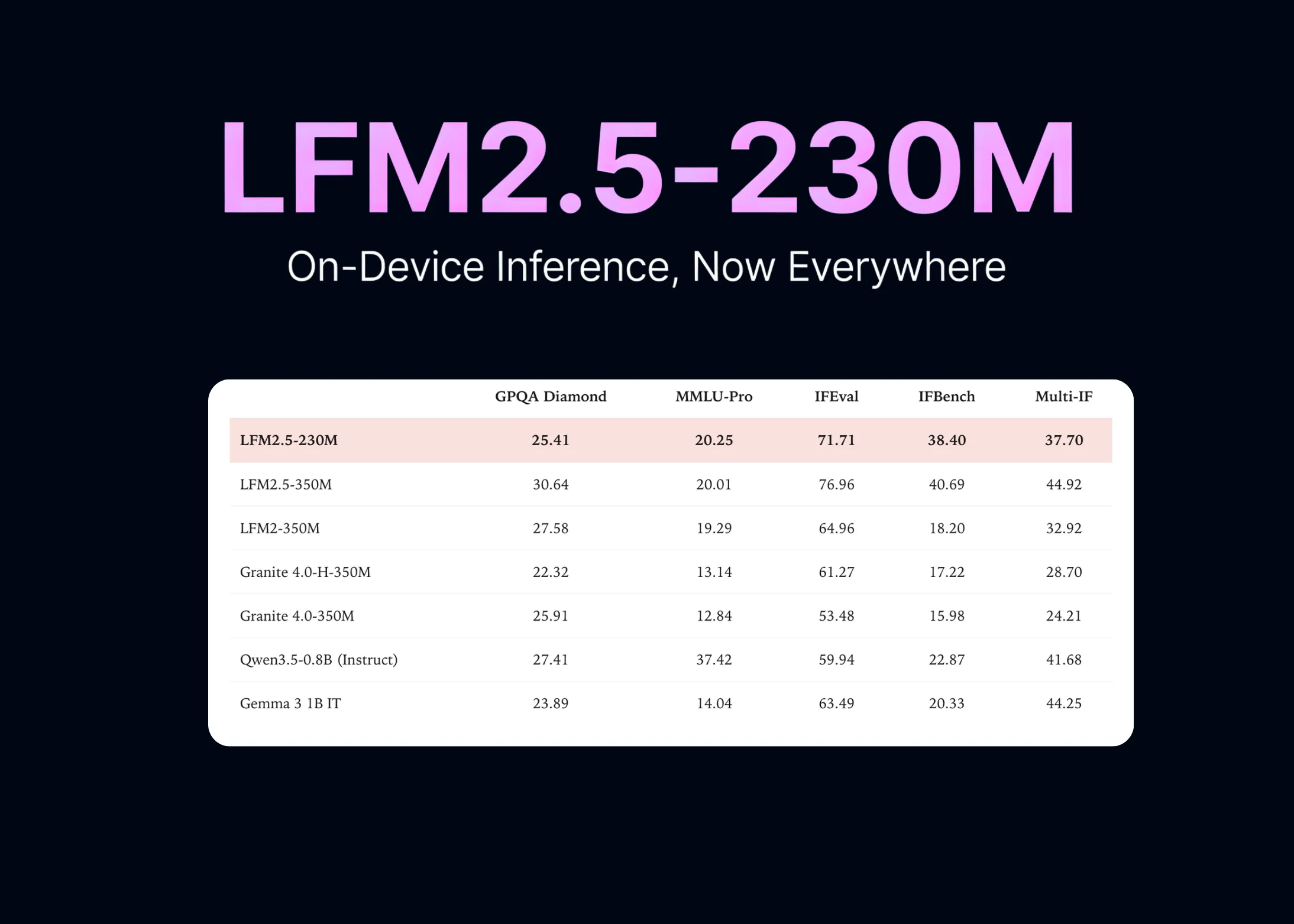
În benchmark-uri, LFM2.5-230M se situează la nivelul unor modele de 1-2 miliarde de parametri, dar cu un consum de resurse mult mai mic. De exemplu, pe sarcini de raționament și generare de text, scorurile sunt comparabile cu Llama 3.2 1B, dar modelul ocupă de trei ori mai puțină memorie. Asta îl face ideal pentru dispozitive cu resurse limitate.
Ce urmează?
Liquid AI a promis că va continua să îmbunătățească LFM2.5-230M și să adauge suport pentru și mai multe framework-uri. De asemenea, lucrează la o versiune mai mare, LFM7B, care va beneficia de aceleași optimizări. Până atunci, LFM2.5-230M este disponibil pe GitHub, cu greutăți pre-antrenate și ghiduri de integrare pentru fiecare framework.
Concluzie
LFM2.5-230M nu este doar un model AI – este o declarație de intenție. Liquid AI demonstrează că viitorul inteligenței artificiale nu stă neapărat în modele tot mai mari, ci în modele mai eficiente, mai portabile și mai accesibile. Cu suportul pentru llama.cpp, MLX, vLLM, SGLang și ONNX, acest model devine un instrument versatil pentru oricine vrea să aducă AI-ul mai aproape de utilizator.
De ce este important:
Această lansare marchează un punct de cotitură în adoptarea AI-ului pe dispozitive locale. Prin suportul pentru cinci framework-uri majore, Liquid AI face ca inferența on-device să fie nu doar posibilă, ci și practică pentru o gamă largă de aplicații – de la asistenți vocali offline la aplicații enterprise care necesită confidențialitate maximă. Este un pas concret spre un AI care nu mai depinde de cloud, ci rulează acolo unde este nevoie: în buzunarul tău, pe biroul tău sau în fabrica ta.




