Subiect: #Benchmark

OpenAI lansează LifeSciBench: un benchmark cu 750 de sarcini pentru evaluarea modelelor AI în cercetarea științifică reală
OpenAI a lansat LifeSciBench, un benchmark cu 750 de sarcini și rubrici create de experți, pentru a evalua capacitatea modelelor AI de a rezolva probleme reale din științele vieții. Primele teste arată că modelele performează bine la sarcini de memorare, dar se luptă cu raționamentul complex.

Moonshot AI lansează Kimi K2.7-Code: un model de codare care raportează o îmbunătățire de +21,8% pe Kimi Code Bench v2 față de K2.6
Moonshot AI a lansat Kimi K2.7-Code, un model de codare care înregistrează o îmbunătățire de +21,8% pe Kimi Code Bench v2 față de versiunea anterioară. Articolul analizează caracteristicile, impactul asupra dezvoltatorilor și provocările asociate, subliniind importanța acestui salt înainte pentru industria AI.

Cele mai bune modele Text-to-Speech (TTS) în 2026: O comparație bazată pe benchmark-uri
Descoperă cele mai bune modele Text-to-Speech din 2026, analizate pe baza benchmark-urilor de naturalete, viteză și suport multilingv. De la ElevenLabs la Google și Microsoft, află care se potrivește nevoilor tale.

Cei mai buni agenți AI pentru dezvoltare software, clasați pe bază de benchmark-uri
Un clasament actualizat al agenților AI pentru dezvoltare software, bazat pe benchmark-uri riguroase. Devin, Copilot și Codex sunt lideri, dar fiecare are puncte forte și slabe. Articolul analizează performanțele și oferă recomandări practice pentru echipele de dezvoltare.
Cline lansează SDK-ul Cline: un runtime open-source pentru agenți AI care alimentează acum CLI și Kanban, extensiile IDE fiind în curs de migrare
Cline a lansat SDK-ul @cline/sdk, un runtime open-source pentru agenți AI, structurat pe patru niveluri, cu suport pentru pluginuri, subagenți, programare CRON și checkpointing. Performanța sa depășește Claude Code pe Terminal Benchmark 2.0, iar extensiile IDE sunt în curs de migrare.

IPO-ul Cerebras aduce miliarde pentru Benchmark, dar VC-ul Eric Vishria aproape că a refuzat întâlnirea
IPO-ul Cerebras a fost un succes uriaș, aducând miliarde pentru Benchmark. Eric Vishria aproape că a refuzat întâlnirea cu startup-ul, dar a fost convins de viziunea fondatorilor. După 8,5 ani de lupte, compania a reușit să devină profitabilă și să atragă clienți mari precum OpenAI și AWS.

GPT-5.5: Cel mai avansat model AI agentic al OpenAI până în prezent
OpenAI a lansat GPT-5.5, cel mai avansat model AI agentic, cu performanțe superioare pe benchmark-uri cheie, dar cu prețuri duble față de predecesor. Articolul analizează capabilitățile, costurile și implicațiile pentru utilizatori.
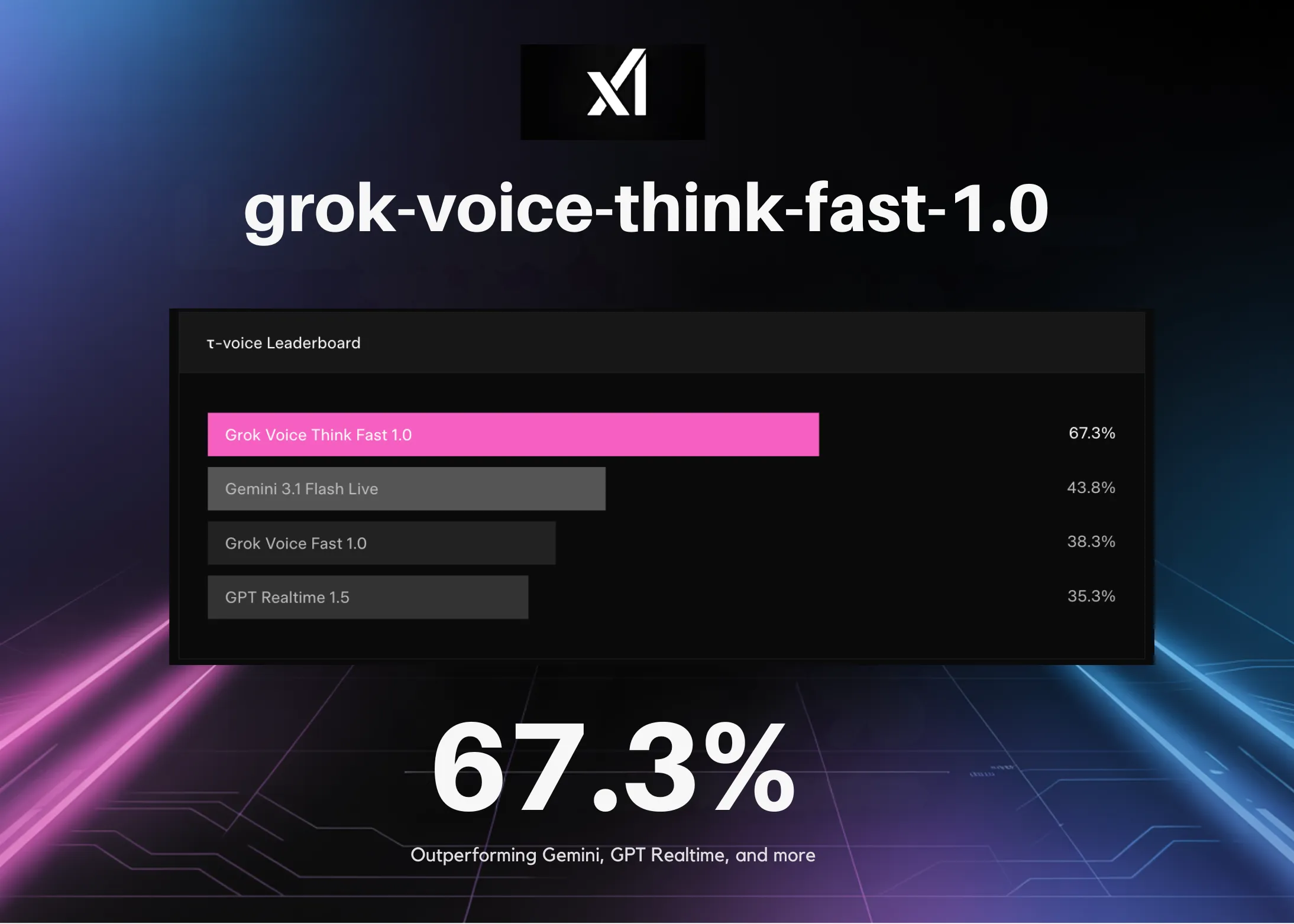
xAI lansează grok-voice-think-fast-1.0: Depășește τ-voice Bench cu 67,3%, surclasând Gemini, GPT Realtime și altele
xAI a lansat grok-voice-think-fast-1.0, un model vocal care a obținut 67,3% pe benchmark-ul τ-voice, depășind Gemini, GPT Realtime și altele. Articolul analizează tehnologia, performanța, aplicațiile și impactul asupra industriei AI.

Sierra, compania lui Bret Taylor, achiziționează startup-ul YC Fragment pentru a întări capacitățile de AI în Europa
Sierra, companía fondată de Bret Taylor și Clay Bavor, a achiziționat startup-ul francez Fragment, sprijinit de Y Combinator, pentru a întări echipa de dezvoltare a agenților AI în Europa — o mișcare care subliniază shift-ul spre AI locală, responsabilă și integrată în piețele regionale.

MiniMax a Lansat Open-Source MiniMax M2.7: Un Model de Agent Auto-Evolutiv care Obține 56,22% pe SWE-Pro și 57,0% pe Terminal Bench 2
MiniMax a lansat open-source modelul M2.7, un agent AI auto-evolutiv care obține rezultate impresionante: 56,22% pe SWE-Pro și 57,0% pe Terminal Bench 2, demonstrând capacitatea sistemelor de a se îmbunătăți autonom.

Cum să Construiești și să Evoluezi un Agent OpenAI Personalizat cu A-Evolve: Benchmarks, Abilități, Memorie și Mutații ale Spațiului de Lucru
Ghid complet pentru dezvoltarea agenților OpenAI adaptivi folosind framework-ul A-Evolve, cu accent pe benchmarks, abilități, memorie pe termen lung și mutații ale spațiului de lucru.
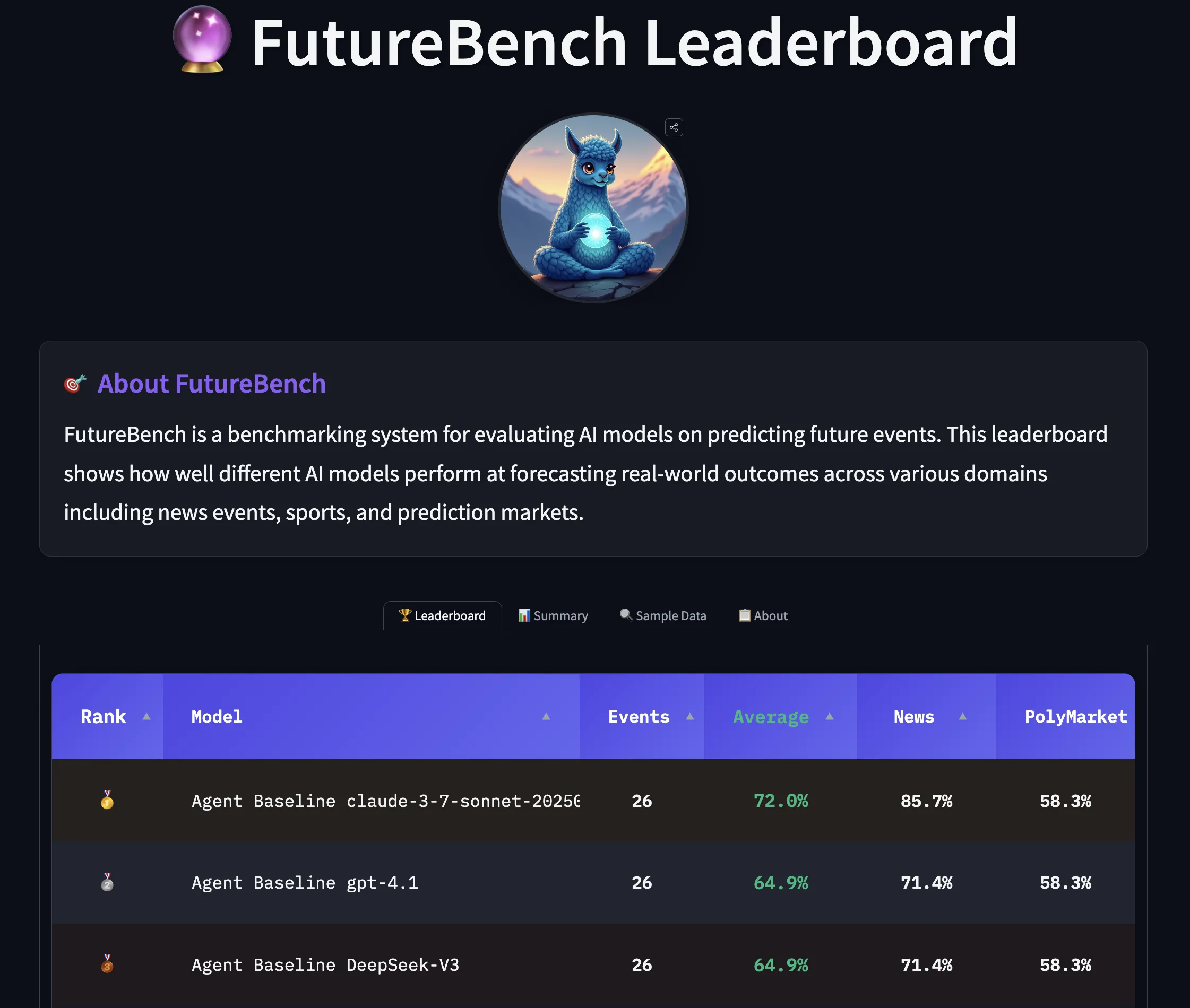
Înapoi în Viitor: Evaluarea Agenților AI în Predicția Evenimentelor Viitoare
Un nou benchmark revoluționar, FutureBench, propune evaluarea agenților AI pe baza capacității lor de a prezice evenimente viitoare, trecând de la testarea memorării faptelor istorice la măsurarea raționamentului complex și a înțelegerii cauzale.