Subiect: #NLP
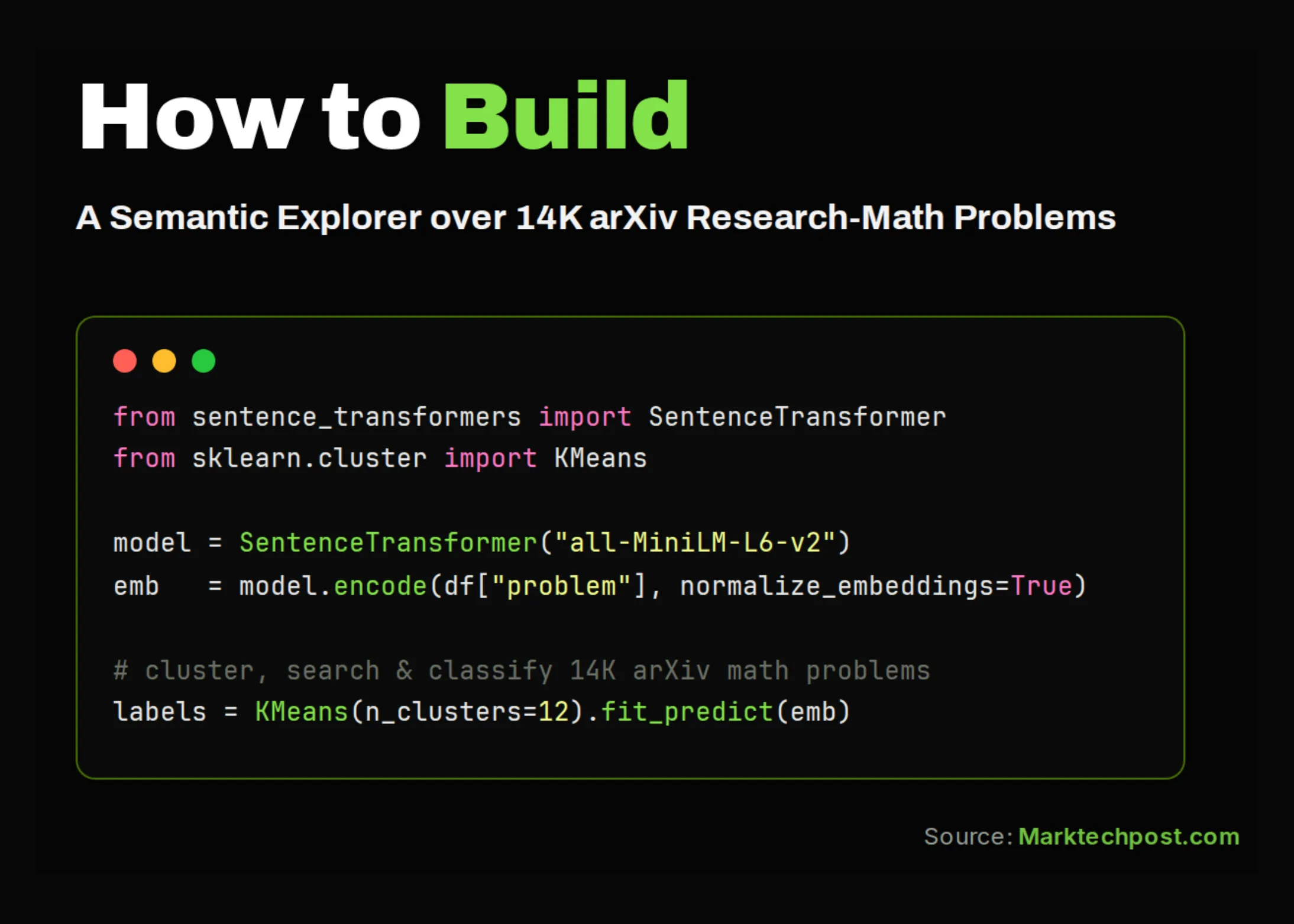
Construirea unui motor de căutare semantică și a unui clasificator de statut deschis pe baza setului de date ResearchMath-14k
Un proiect inovator construiește un motor de căutare semantică și un clasificator de statut deschis pe baza setului de date ResearchMath-14k, facilitând accesul rapid la articole de matematică și identificarea resurselor open access. Articolul detaliază tehnologia, provocările și impactul asupra comunității academice.
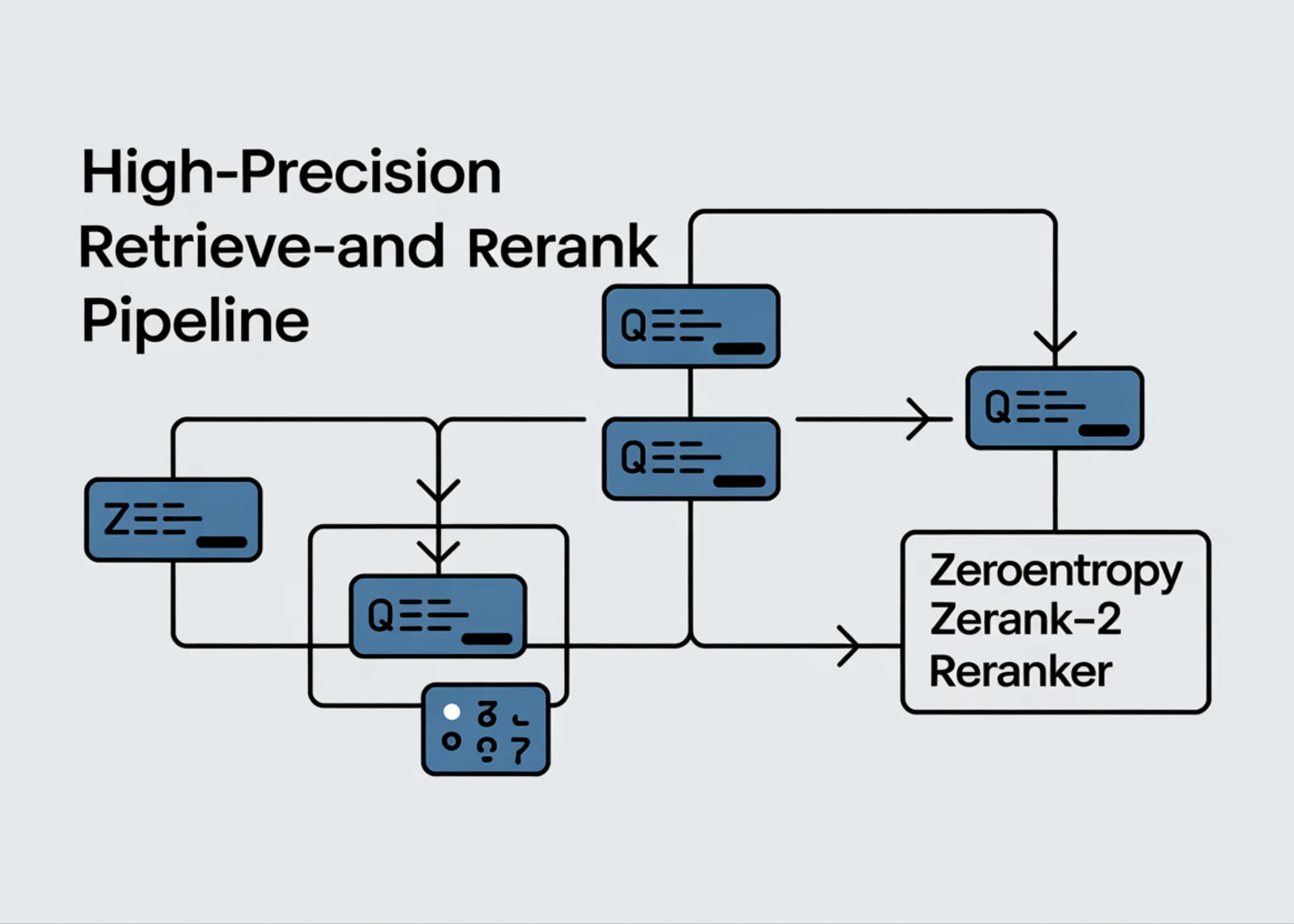
Cum să construiești o conductă de tip Retrieve-and-Rerank de înaltă precizie cu ZeroEntropy Zerank-2 Reranker
Descoperă cum să construiești un sistem de căutare inteligent folosind ZeroEntropy Zerank-2, un reranker open-source care îmbunătățește semnificativ precizia regăsirii informațiilor. Ghid practic cu cod și exemple.
Microsoft AI Lansarea Harrier-OSS-v1: Noua Familie de Modele Multilingve de Embedding care Depășesc Starea Actuală a Tehnologiei
Microsoft AI a lansat familia de modele multilingve Harrier-OSS-v1, care stabilește un nou record pe benchmark-ul Multilingual MTEB v2, oferind capabilități de embedding fără precedent pentru aplicații AI globale.

Salesforce AI Research lansează VoiceAgentRAG: Un Router Dual-Agent de Memorie care Reduce Latența Recuperării RAG Vocal cu 316x
Salesforce AI Research a dezvoltat VoiceAgentRAG, un sistem revoluționar cu router dual-agent de memorie care reduce latența recuperării informațiilor în sistemele RAG vocale de 316 ori. Tehnologia utilizează agenți inteligenți de rutare și optimizare pentru a anticipa necesitățile informaționale și a accelera accesul la date, eliminând pauzele inconfortabile din conversațiile vocale cu AI și deschizând noi posibilități pentru asistenți virtuali enterprise în timp real.

Ettin Suite: O nouă eră în arhitectura AI – Encodere și Decodere de ultimă generație
Ettin Suite introduce primele modele pereche (encodere și decodere) antrenate identic, oferind o comparație riguroasă și performanțe de ultimă oră. Proiectul depășește standardele actuale precum ModernBERT și Llama 3.2, demonstrând superioritatea specifică a fiecărei arhitecturi în funcție de task-ul dorit.

📚 3LM: Un nou punct de referință pentru modelele de limbaj arabe în domeniile STEM și programare
3LM (علم) reprezintă primul benchmark dedicat evaluării modelelor de limbaj arabe în domeniile STEM și generarea de cod, adresând o lacună majoră în peisajul actual al NLP-ului arab prin introducerea a trei seturi de date distincte: întrebări educaționale native, întrebări sintetice de dificultate ridicată și sarcini de programare traduse.

🇵🇭 FilBench: Pot modelele de limbaj să înțeleagă și să genereze filipineză?
FilBench este o suită de evaluare lansată în 2025 pentru a testa capacitatea modelelor AI de a înțelege și genera limbaj în filipineză, tagalog și cebuano. Studiul relevă că deși modelele regionale rămân în urma GPT-4, ele oferă o alternativă cost-eficientă și promițătoare pentru comunitățile locale.

NVIDIA lansează un set de date masiv de raționament multilingv: 6 milioane de intrări pentru a democratiza inteligența artificială deschisă
NVIDIA lansează un set de date masiv de raționament multilingv, extinzând suportul pentru AI-ul deschis. Noul model Nemotron Nano 2 9B introduce o arhitectură hibridă și un „buget de gândire” configurabil, promițând costuri de raționament cu 60% mai mici.

EmbeddingGemma: Noul model de embedding eficient de la Google revoluționează căutarea semantică pe dispozitive mobile
Google lansează EmbeddingGemma, un model de embedding multilingv de 308M parametri, optimizat pentru dispozitive mobile și performanță de top în căutarea semantică și RAG.

mmBERT: ModernBERT devine multilingv – o nouă eră pentru modelele de limbaj
mmBERT reprezintă o evoluție majoră în domeniul modelelor de limbaj multilingve, fiind primul care depășește performanțele XLM-R. Antrenat pe peste 3 trilioane de tokeni în 1800 de limbi, modelul introduce tehnici inovatoare de antrenament progresiv și fuzionare, oferind simultan performanță superioară și eficiență computațională ridicată.

Familia Palmyra-mini: Modele puternice, ușoare și pregătite pentru raționament complex
Familia Palmyra-mini redefinesc standardele modelelor de limbaj ușoare, combinând eficiența computațională cu capacități avansate de raționament. Descoperă noile modele „thinking”, antrenate cu Chain of Thought, care obțin scoruri remarcabile pe benchmark-uri precum GSM8K și AMC23.

Prezentând RTEB: Un Noua Standard pentru Evaluarea Recuperării Datelor în Era Inteligenței Artificiale
RTEB (Retrieval Embedding Benchmark) redefinesc evaluarea modelelor de embedding prin utilizarea unei strategii hibride, care combină seturi de date deschise și private pentru a combate supra-ajustarea și a oferi o măsură reală a capacității de generalizare în domenii precum finanțe, drept, cod și sănătate.