Subiect: #Machine Learning

Cum să Construiești un Pipeline de Generare AI cu Gemma 3 1B Instruct Pregătit pentru Producție,folosind Hugging Face Transformers, Șabloane de Chat și Inferență pe Colab
Ghid comprehensiv pentru construirea unui pipeline de generare AI production-ready cu modelul Gemma 3 1B Instruct, folosind Hugging Face Transformers, șabloane de chat și inferență pe Google Colab.

Cum să Construiești și să Evoluezi un Agent OpenAI Personalizat cu A-Evolve: Benchmarks, Abilități, Memorie și Mutații ale Spațiului de Lucru
Ghid complet pentru dezvoltarea agenților OpenAI adaptivi folosind framework-ul A-Evolve, cu accent pe benchmarks, abilități, memorie pe termen lung și mutații ale spațiului de lucru.

Nomadic AI atrage 8,4 milioane de dolari pentru a organiza fluxul masiv de date provenit de la vehiculele autonome
Nomadic AI, startup fondat de foști studenți Harvard, a atras 8,4 milioane de dolari pentru a ajuta companiile din domeniul vehiculelor autonome să organizeze și să valorifice imensul volum de date video generate de flotele lor, transformând înregistrările brute în seturi de date structurate și accesibile.

Inteligența Artificială a Contribuit la Selectarea Primelor O Mie de Ținte în Iran
Profesorul Toby Walsh de la Universitatea New South Wales Sydney explică rolul inteligenței artificiale în conflictul dintre SUA, Israel și Iran, în timp ce planul diplomatic propus de Trump nu este considerat un început autentic de către Tehran.
Studiu Ocorian: Birourile familiale adoptă pe scară largă inteligența artificială pentru analiza datelor financiare
Un studiu Ocorian realizat pe 16 teritorii arată că 86% dintre birourile familiale utilizează inteligența artificială pentru analiza datelor financiare, reprezentând active de 119,37 miliarde de dolari. Adoptarea vizează detectarea anomaliilor, automatizarea raportării și conformitatea regulatorie.

Salesforce AI Research lansează VoiceAgentRAG: Un Router Dual-Agent de Memorie care Reduce Latența Recuperării RAG Vocal cu 316x
Salesforce AI Research a dezvoltat VoiceAgentRAG, un sistem revoluționar cu router dual-agent de memorie care reduce latența recuperării informațiilor în sistemele RAG vocale de 316 ori. Tehnologia utilizează agenți inteligenți de rutare și optimizare pentru a anticipa necesitățile informaționale și a accelera accesul la date, eliminând pauzele inconfortabile din conversațiile vocale cu AI și deschizând noi posibilități pentru asistenți virtuali enterprise în timp real.

Ghid Complet de Programare pentru Explorarea Pipeline-ului de Agente Nanobot: De la Configurarea Instrumentelor și Memoriei până la Competențe, Subagenți și Programare Cron
Nanobot oferă o platformă revoluționară pentru dezvoltarea agenților AI autonomi, combinând un sistem modular de instrumente și memorie cu competențe avansate, arhitectură de subagenți și programare temporală robustă.

Evaluarea instrumentelor de prognozare a prețurilor bazate pe Inteligență Artificială în piețele valutare
Pe măsură ce inteligența artificială devine o forță motrică în predicțiile financiare, fiabilitatea instrumentelor sale de prognozare este supusă unei examinări tot mai atente. Articolul explorează decalajul dintre acuratețea teoretică din testele controlate și performanța reală în piețele valutare volatile, analizând arhitectura modelelor, metricile de evaluare esențiale și importanța gestionării riscurilor în implementarea strategiilor de tranzacționare algoritmice.

Ettin Suite: O nouă eră în arhitectura AI – Encodere și Decodere de ultimă generație
Ettin Suite introduce primele modele pereche (encodere și decodere) antrenate identic, oferind o comparație riguroasă și performanțe de ultimă oră. Proiectul depășește standardele actuale precum ModernBERT și Llama 3.2, demonstrând superioritatea specifică a fiecărei arhitecturi în funcție de task-ul dorit.

Accelerarea implementării modelelor lingvistice mari (LLM) de pe Hugging Face prin NVIDIA NIM: O revoluție în infrastructura AI enterprise
NVIDIA anunță integrarea microserviciilor NIM cu platforma Hugging Face, deblocând accesul rapid la peste 100.000 de modele LLM. Soluția oferă un singur container Docker capabil să optimizeze automat implementarea, detectând arhitectura și selectând backend-ul ideal pentru performanță maximă.

Prezentarea noii interfețe `hf`: un CLI Hugging Face mai rapid și mai prietenos ✨
Hugging Face lansează un nou CLI, `hf`, înlocuind vechiul `huggingface-cli` cu o structură mai clară și intuitivă. Noul instrument aduce o organizare logică a comenzilor, suport pentru migrare și introduce serviciul Hugging Face Jobs pentru rularea de scripturi pe infrastructură dedicată, cu facturare pay-as-you-go.
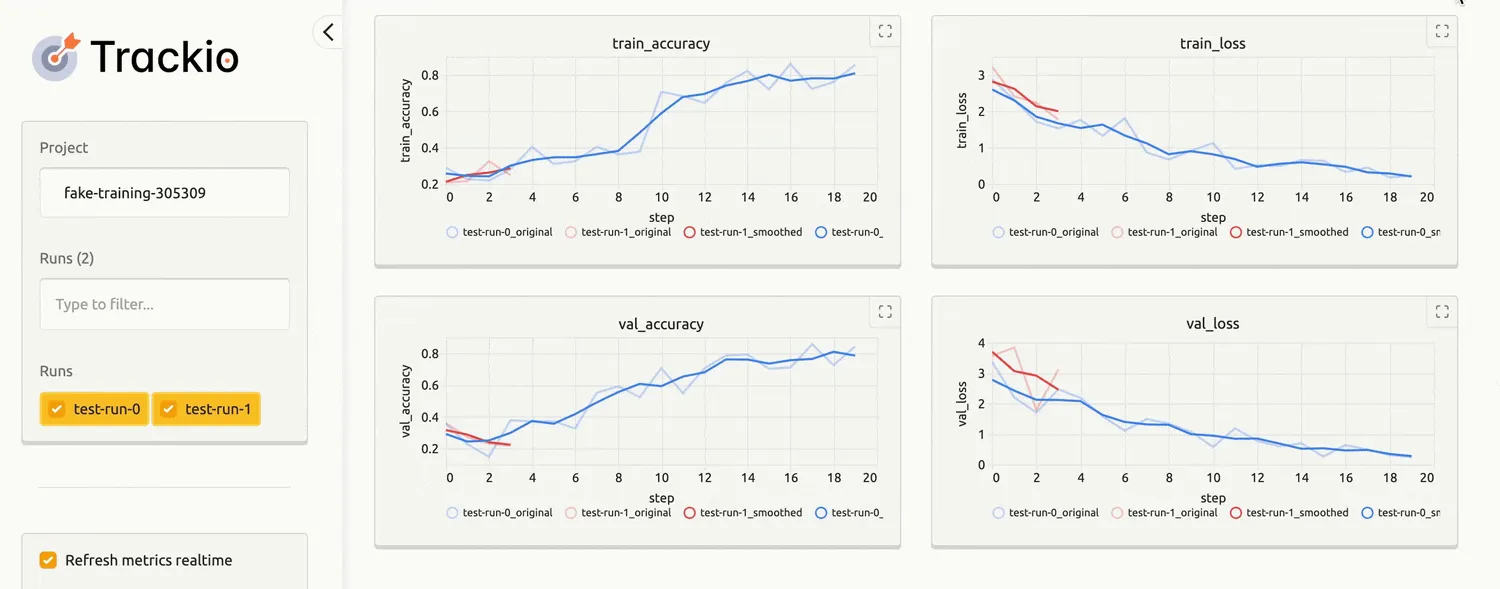
Prezentare Trackio: O bibliotecă ușoară pentru urmărirea experimentelor de la Hugging Face
Hugging Face lansează Trackio, o bibliotecă Python open-source și ușoară pentru urmărirea experimentelor de machine learning, oferind o alternativă gratuită și flexibilă, cu integrare nativă în ecosistemul Hugging Face și focus pe transparență și simplitate.